 Golang源码系列-sync.Map
Golang源码系列-sync.Map
Golang的内建map是不支持并发写操作的,当多个Goroutine操作同一个map,会产生报错:fatal error: concurrent map writes, 因此官方另外引入了sync.Map来满足并发编程中的应用。
# 1. 数据结构
在分析sync.map各方法源码之前,我们先了解一下关联的数据结构。
map的数据结构如下:
type Map struct {
// 当涉及到脏数据(dirty)操作时候,需要使用这个锁
mu Mutex
// 只读的数据,实际数据类型为 readOnly
// 读不需要加锁,只需要通过 atomic 加载最新的指针即可
read atomic.Value
// 最新写入的数据
// dirty 包含部分map的键值对,如果操作需要mutex获取锁
// 最后dirty中的元素会被全部提升到read里的map去
dirty map[interface{}]*entry
// 计数器,每次需要读 dirty 则 +1, 用于记录read中没有的数据而在dirty中有的数据的数量
// 也就是说如果read不包含这个数据,会从dirty中读取,并misses+1
// 当misses的数量等于dirty的长度,就会将dirty中的数据迁移到read中
misses int
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
其中readOnly的数据结构为:
type readOnly struct {
// 内建 map,包含所有只读数据,不会进行任何的数据增加和删除操作
// 但是可以修改entry的指针因为这个不会导致map的元素移动
m map[interface{}]*entry
// 标志位,如果为true则表示 dirty 里存在 read 里没有的 key,通过该字段决定是否加锁读 dirty
amended bool
}
1
2
3
4
5
6
7
2
3
4
5
6
7
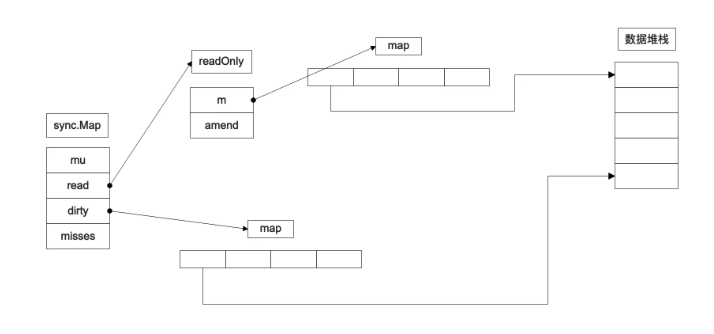
readOnly.m和Map.dirty存储的值类型是*entry,它包含一个指针p, 指向存储的value值,entry结构如下:
type entry struct {
p unsafe.Pointer // 等同于 *interface{}
}
1
2
3
4
2
3
4
属性 p 有三种状态:
- p == nil: 键值已经被删除,且 m.dirty == nil
- p == expunged: 键值已经被删除,但 m.dirty!=nil 且 m.dirty 不存在该键值(expunged 实际是空接口指针)
- 除以上情况,则键值对存在,存在于 m.read.m 中,如果 m.dirty!=nil 则也存在于 m.dirty
通过下面的示意图来总结上面的结构体(图片来自网络):
# 2. 常用方法源码分析
# 2.1 Load
func (m *Map) Load(key interface{}) (value interface{}, ok bool) {
// 首先尝试从 read 中读取 readOnly 对象
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
// 如果不存在则尝试从 dirty 中获取
if !ok && read.amended {
m.mu.Lock()
// 由于上面 read 获取没有加锁,为了安全再检查一次
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
// 确实不存在则从 dirty 获取
if !ok && read.amended {
e, ok = m.dirty[key]
// 调用 miss 的逻辑
m.missLocked()
}
m.mu.Unlock()
}
if !ok {
return nil, false
}
// 从 entry.p 读取值
return e.load()
}
func (m *Map) missLocked() {
m.misses++
if m.misses < len(m.dirty) {
return
}
// 当 miss 积累过多,会将 dirty 存入 read,然后 将 amended = false,且 m.dirty = nil
m.read.Store(readOnly{m: m.dirty})
m.dirty = nil
m.misses = 0
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
# 2.2 Store
func (m *Map) Store(key, value interface{}) {
read, _ := m.read.Load().(readOnly)
// 如果 read 里存在,则尝试存到 entry 里
if e, ok := read.m[key]; ok && e.tryStore(&value) {
return
}
// 如果上一步没执行成功,则要分情况处理
m.mu.Lock()
read, _ = m.read.Load().(readOnly)
// 和 Load 一样,重新从 read 获取一次
if e, ok := read.m[key]; ok {
// 情况 1:read 里存在
if e.unexpungeLocked() {
// 如果 p == expunged,则需要先将 entry 赋值给 dirty(因为 expunged 数据不会留在 dirty)
m.dirty[key] = e
}
// 用值更新 entry
e.storeLocked(&value)
} else if e, ok := m.dirty[key]; ok {
// 情况 2:read 里不存在,但 dirty 里存在,则用值更新 entry
e.storeLocked(&value)
} else {
// 情况 3:read 和 dirty 里都不存在
if !read.amended {
// 如果 amended == false,则调用 dirtyLocked 将 read 拷贝到 dirty(除了被标记删除的数据)
m.dirtyLocked()
// 然后将 amended 改为 true
m.read.Store(readOnly{m: read.m, amended: true})
}
// 将新的键值存入 dirty
m.dirty[key] = newEntry(value)
}
m.mu.Unlock()
}
func (e *entry) tryStore(i *interface{}) bool {
for {
p := atomic.LoadPointer(&e.p)
if p == expunged {
return false
}
if atomic.CompareAndSwapPointer(&e.p, p, unsafe.Pointer(i)) {
return true
}
}
}
func (e *entry) unexpungeLocked() (wasExpunged bool) {
return atomic.CompareAndSwapPointer(&e.p, expunged, nil)
}
func (e *entry) storeLocked(i *interface{}) {
atomic.StorePointer(&e.p, unsafe.Pointer(i))
}
func (m *Map) dirtyLocked() {
if m.dirty != nil {
return
}
read, _ := m.read.Load().(readOnly)
m.dirty = make(map[interface{}]*entry, len(read.m))
for k, e := range read.m {
// 判断 entry 是否被删除,否则就存到 dirty 中
if !e.tryExpungeLocked() {
m.dirty[k] = e
}
}
}
func (e *entry) tryExpungeLocked() (isExpunged bool) {
p := atomic.LoadPointer(&e.p)
for p == nil {
// 如果有 p == nil(即键值对被 delete),则会在这个时机被置为 expunged
if atomic.CompareAndSwapPointer(&e.p, nil, expunged) {
return true
}
p = atomic.LoadPointer(&e.p)
}
return p == expunged
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
# 2.3 Delete
删除并不是简单的将key从map中删除。
func (m *Map) Delete(key interface{}) {
m.LoadAndDelete(key)
}
// LoadAndDelete 作用等同于 Delete,并且会返回值与是否存在
func (m *Map) LoadAndDelete(key interface{}) (value interface{}, loaded bool) {
// 获取逻辑和 Load 类似,read 不存在则查询 dirty
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
if !ok && read.amended {
m.mu.Lock()
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
if !ok && read.amended {
e, ok = m.dirty[key]
m.missLocked()
}
m.mu.Unlock()
}
// 查询到 entry 后执行删除
if ok {
// 将 entry.p 标记为 nil,数据并没有实际删除
// 真正删除数据并被被置为 expunged,是在 Store 的 tryExpungeLocked 中
return e.delete()
}
return nil, false
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
根据上面的逻辑可以看出,删除的时候,存在以下几种情况:
- read中没有,且Map存在修改,则尝试删除dirty中的map中的key;
- read中没有,且Map不存在修改,那就是没有这个key,无需操作;
- read中有,尝试将key对应的值设置为nil,后面读取的时候就知道被删了,因为dirty中map的值跟read的map中的值指向的都是同一个地址空间,所以,修改了read也就是修改了dirty
# 2.4 Range
遍历的逻辑比较简单,Map只有两种状态,被修改过和没有修改过。修改过:将dirty的指针交给read,read就是最新的数据了,然后遍历read的map;没有修改过:遍历read的map。
func (m *Map) Range(f func(key, value interface{}) bool) {
read, _ := m.read.Load().(readOnly)
if read.amended {
m.mu.Lock()
read, _ = m.read.Load().(readOnly)
if read.amended {
read = readOnly{m: m.dirty}
m.read.Store(read)
m.dirty = nil
m.misses = 0
}
m.mu.Unlock()
}
for k, e := range read.m {
v, ok := e.load()
if !ok {
continue
}
if !f(k, v) {
break
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 3. sycn.Map原理概括
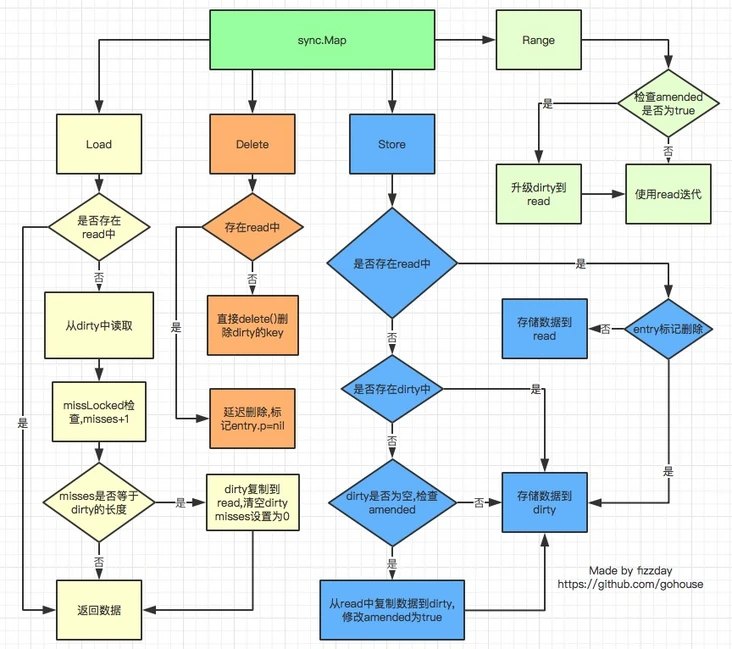
sync.Map的实现原理可概括为:
- 通过
read和dirty两个字段将读写分离,读的数据存在只读字段read上,将最新写入的数据则存在dirty字段上; - 读取时会先查询
read,不存在再查询dirty,写入时则只写入dirty; - 读取
read并不需要加锁,而读或写dirty都需要加锁; - 另外有
misses字段来统计read被穿透的次数(被穿透指需要读dirty的情况), 超过一定次数则将dirty数据同步到read上; - 对于删除数据则直接通过标记来延迟删除
大概流程可以用下图该概括(图片来自网络):
# 4. 总结
通过以上源码分析,可见sync.Map的原理很简单,通过这种读写分离的设计,使用空间换时间,解决了并发情况的写入安全,又使读取速度在大部分情况可以接近内建map,非常适合读多写少的情况。
上次更新: 2022/12/01, 11:09:34