 Golang开发实践万字总结
Golang开发实践万字总结
# 1. 基本知识
# 1.1 数组与slice
# 1.1.1 数组
我们先看看数组有哪些定义方式:
var a [3]int // 定义长度为 3 的 int 型数组, 元素全部为 0
var b = [...]int{1, 2, 3} // 定义长度为 3 的 int 型数组, 元素为 1, 2, 3
var c = [...]int{2: 3, 1: 2} // 定义长度为 3 的 int 型数组, 元素为 0, 2, 3
var d = [...]int{1, 2, 4: 5, 6} // 定义长度为 6 的 int 型数组, 元素为 1, 2, 0, 0, 5, 6
2
3
4
Go语言中数组是值语义,一个数组变量即表示整个数组,它并不是隐式的指向第一个元素的指针(比如C语言的数组),而是一个完整的值。 当一个数组变量被赋值或者被传递的时候,实际上会复制整个数组。如果数组较大的话,数组的赋值也会有较大的开销,为了避免复制数组带来的开销,可以传递一个指向数组的指针,但是数组指针并不是数组。
对数组类型而言,数组的长度是数组类型的组成部分,不同长度或不同类型的数据组成的数组都是不同的类型。
# 1.1.2 空数组
长度为0的数组在内存中并不占用空间。空数组虽然很少直接使用,但是可以用于强调某种特有类型的操作时避免分配额外的内存空间,比如用于管道的同步操作(同空struct效果类似,充分利用其不占内存空间特性):
c1 := make(chan [0]int)
go func() {
fmt.Println("c1")
c1 <- [0]int{}
}()
<-c1
2
3
4
5
6
# 1.1.3 数组与slice的区别
- 数组是一个由固定长度的特定类型元素组成的序列;
- 切片是可以动态增长和收缩的序列
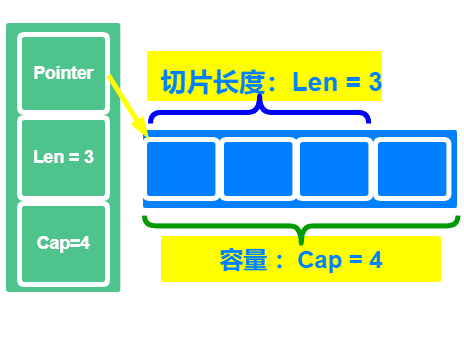
- slice的底层是一个数据结构,有指向底层数组的指针,len长度,cap容量组成;
type slice struct {
array unsafe.Pointer
len int
cap int
}
2
3
4
5
# 1.1.4 数组转成切片
除了通过make创建slice, 还可以使用数组来创建slice时,slice将与原数组共用一部分内存。
slice := array[5:7]
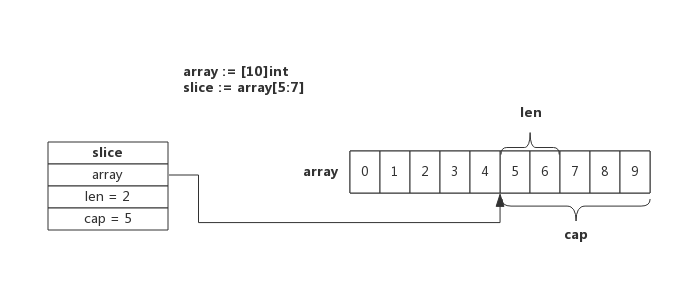
数组和切片操作可能作用于同一块内存,这也是使用过程中需要注意的地方(也是可能会引发内存泄漏的地方)。
# 1.1.5 slice扩容
使用append向slice追加元素时,如果slice空间不足,将会触发slice扩容,扩容实际上是重新分配一块更大的内存,将原slice数据拷贝进新slice,然后返回新slice,扩容后再将数据追加进去(此时底层将指向新的数组,所以之前说数组和切片操作是可能作用于同一块内存)。
# 1.1.5.1 头部追加和尾部追加
除了在切片的尾部追加,我们还可以在切片的开头添加元素:
var a = []int{1,2,3}
a = append([]int{0}, a...) // 在开头添加 1 个元素
a = append([]int{-3,-2,-1}, a...) // 在开头添加 1 个切片
2
3
在开头一般都会导致内存的重新分配,而且会导致已有的元素全部复制 1 次。因此,从切片的开头添加元素的性能一般要比从尾部追加元素的性能差很多。
# 1.1.5.2 slice扩容规则
- 如果原slice容量小于1024,则新slice容量将扩大为原来2倍(cap < 1024, x2);
- 如果原slice容量大于1024,则新slice容量将扩大为原来1.25倍(cap >1024, x1.25);
- 使用append()向slice添加一个元素的实现步骤如下:
- 假如slice容量够用,则将新元素追加进去,slice.len++,返回原slice.
- 原slice容量不够,则将slice先扩容,扩容后得到新slice; 将新元素追加进新slice,slice.len++,返回新的slice。
# 1.1.5.3 可能的内存泄漏
切片操作并不会复制底层的数据, 底层的数组会被保存在内存中,直到它不再被引用。但是有时候可能会因为一个小的内存引用而导致底层整个数组处于被使用的状态,这会延迟自动内存回收器对底层数组的回收。
案例1:
func FindPhoneNumber(filename string) []byte {
b, _ := ioutil.ReadFile(filename)
return regexp.MustCompile("[0-9]+").Find(b)
}
2
3
4
改进后:
func FindPhoneNumber(filename string) []byte {
b, _ := ioutil.ReadFile(filename)
b = regexp.MustCompile("[0-9]+").Find(b)
# 生成新的slice,解决数组没有被GC
return append([]byte{}, b...)
}
2
3
4
5
6
案例2:
var a []*int{ ... }
a = a[:len(a)-1] // 被删除的最后一个元素依然被引用, 可能导致 GC 操作被阻碍
2
改进后:
var a []*int{ ... }
a[len(a)-1] = nil // GC 回收最后一个元素内存
a = a[:len(a)-1] // 从切片删除最后一个元素
2
3
# 1.1.5.4 总结
- slice的append操作在cap容量不足情况下,会导致slice扩容,涉及到内存申请和内存拷贝,会影响性能,所以我们在创建切片时,最好指定slice容量,避免出现扩容操作;
- 使用copy()方法来进行slice的复制,可避免append产生临时slice;
# 1.1.6 如何判断 2 个字符串切片(slice) 是相等的?
go语言中可以使用反射reflect.DeepEqual(a, b)判断 a、b 两个切片是否相等,但是通常不推荐这么做,使用反射非常影响性能。
通常采用的方式如下,遍历比较切片中的每一个元素(注意处理越界的情况)。
func StringsliceEqual(a, b []string) bool {
if len(a) != len(b) {
return false
}
if (a == nil) != (b == nil) {
return false
}
b = b[:len(a)]
for i, v := range a {
if v != b[i] {
return false
}
}
return true
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 1.1.7 切片是在栈上分配内存的还是在堆?
- 切片的容量有关:当切片的容量非常小的时候,直接在栈上分配内存,如果非常大则会直接在堆上分配内存,这点与数组是类似的。
- 切片指针的变量是否发生了逃逸:我们可以使用go build --gcflags来观察变量内存的分配过程:
# 1.2 字符串
# 1.2.1 字符串特性
一个字符串是一个不可改变的字节序列,字符串通常是用来包含人类可读的文本数据,和数组不同的是,字符串的元素不可修改,是一个只读的字节数组。
# 1.2.2 字符串拼接
拼接字符串的方式有:+ , fmt.Sprintf , strings.Builder, bytes.Buffer, strings.Join
"+":使用+操作符进行拼接时,会对字符串进行遍历,计算并开辟一个新的空间来存储原来的两个字符串。fmt.Sprintf:由于采用了接口参数,必须要用反射获取值,因此有性能损耗。strings.Builder:用WriteString()进行拼接,内部实现是指针+切片,同时String()返回拼接后的字符串,它是直接把[]byte转换为string,从而避免变量拷贝。bytes.Bufferbytes.Buffer是一个一个缓冲byte类型的缓冲器,这个缓冲器里存放着都是byte,bytes.buffer底层也是一个[]byte切片。strings.join:strings.join也是基于strings.builder来实现的,并且可以自定义分隔符,在join方法内调用了b.Grow(n)方法,这个是进行初步的容量分配,而前面计算的n的长度就是我们要拼接的slice的长度,因为我们传入切片长度固定,所以提前进行容量分配可以减少内存分配,很高效。
性能比较:
strings.Join ≈ strings.Builder > bytes.Buffer > "+" > fmt.Sprintf
5种拼接方法的实例代码:
func main(){
a := []string{"a", "b", "c"}
//方式1:+
ret := a[0] + a[1] + a[2]
//方式2:fmt.Sprintf
ret := fmt.Sprintf("%s%s%s", a[0],a[1],a[2])
//方式3:strings.Builder
var sb strings.Builder
sb.WriteString(a[0])
sb.WriteString(a[1])
sb.WriteString(a[2])
ret := sb.String()
//方式4:bytes.Buffer
buf := new(bytes.Buffer)
buf.Write(a[0])
buf.Write(a[1])
buf.Write(a[2])
ret := buf.String()
//方式5:strings.Join
ret := strings.Join(a,"")
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 1.2.3 什么是 rune 类型?
Go语言的字符有以下两种:
- uint8类型,或者叫byte型,代表了ASCII码的一个字符。
- rune类型,代表一个UTF-8字符,当需要处理中文、日文或者其他复合字符时,则需要用到rune类型。rune类型等价于int32类型(4个字节)。
func TestRuneUse(t *testing.T) {
var a = '中' // rune类型
fmt.Println(reflect.TypeOf(a).Name()) // int32
fmt.Println(a)
}
=== RUN TestRuneUse
int32
20013
--- PASS: TestRuneUse (0.00s)
PASS
---
2
3
4
5
6
7
8
9
10
11
12
# 1.3 Map
# 1.3.1 Map实现原理
Go中map的基于哈希表(也被称为散列表)实现。
# 1.3.1.1 哈希函数
哈希函数(常被称为散列函数)是可以用于将任意大小的数据映射到固定大小值的函数,常见的包括MD5、SHA系列等。一个设计优秀的哈希函数应该包含以下特性:
均匀性:一个好的哈希函数应该在其输出范围内尽可能均匀地映射,也就是说,应以大致相同的概率生成输出范围内的每个哈希值。效率高:哈希效率要高,即使很长的输入参数也能快速计算出哈希值。可确定性:哈希过程必须是确定性的,这意味着对于给定的输入值,它必须始终生成相同的哈希值。雪崩效应:微小的输入值变化也会让输出值发生巨大的变化。不可逆:从哈希函数的输出值不可反向推导出原始的数据。
# 1.3.1.2 哈希冲突
哈希函数是将任意大小的数据映射到固定大小值的函数。那么可以预见到,即使哈希函数设计得足够优秀,几乎每个输入值都能映射为不同的哈希值。但是,当输入数据足够大,大到能超过固定大小值的组合能表达的最大数量数,冲突将不可避免!
比较常用的Hash冲突解决方案有链地址法和开放寻址法, Golang解决哈希冲突的方式是链地址法,即通过使用数组+链表的数据结构来表达map。
在了解链地址法之前,先明确两个概念:
哈希桶:哈希桶(也称为槽,类似于抽屉原理中的一个抽屉)可以先简单理解为相同哈希值的元素组成的存储空间。装载因子:装载因子是表示哈希表中元素的填满程度。它的计算公式:装载因子=填入哈希表中的元素个数/哈希表的长度。装载因子越大,填入的元素越多,空间利用率就越高,但发生哈希冲突的几率就变大。反之,装载因子越小,填入的元素越少,冲突发生的几率减小,但空间浪费也会变得更多,而且还会提高扩容操作的次数。装载因子也是决定哈希表是否进行扩容的关键指标。
# 1.3.1.3 链地址法
链地址法的思想就是将映射在一个桶里的所有元素用链表串起来。
下面以一个简单的哈希函数 H(key) = key MOD 7(除数取余法)对一组元素 [50, 700, 76, 85, 92, 73, 101] 进行映射,通过图示来理解链地址法处理Hash冲突的处理逻辑。

链地址法解决冲突的方式是当发生冲突,就用单链表组织起来,当不存在哈希碰撞时查找复杂度为O(1),存在哈希碰撞时复杂度为O(N)。
# 1.3.1.4 HashKey
Golang中hash key经过哈希计算后得到64bit位的哈希值。如果B=5,buckets数组的长度,即桶的数量是32(2的5次方)。 例如,现要置一key于map中,该key经过哈希后,得到的哈希值如下:

前面我们知道,哈希值低位(low-order bits)用于选择桶,哈希值高位(high-order bits)用于在一个独立的桶中区别出键。
当B等于5时,那么我们选择的哈希值低位也是5位,即01010,它的十进制值为10,代表10号桶。再用哈希值的高8位,找到此key在桶中的位置。最开始桶中还没有key,那么新加入的key和value就会被放入第一个key空位和value空位。
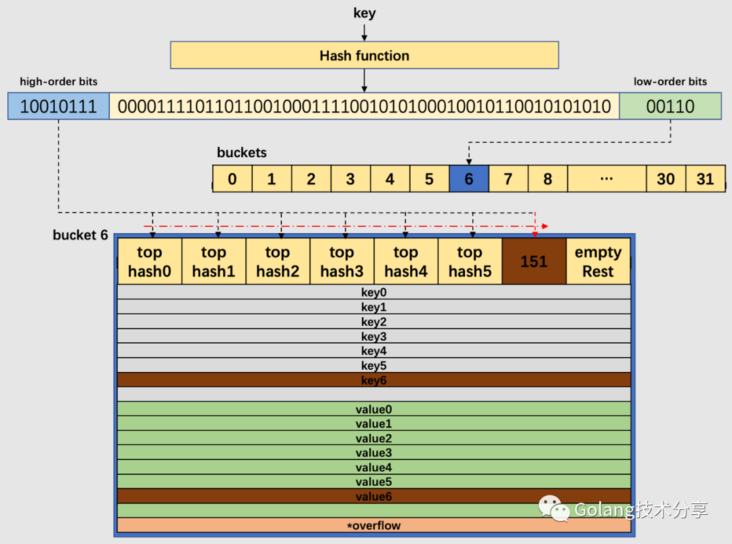
上图中的B值为5,所以桶的数量为32。通过哈希函数计算出待插入key的哈希值,低5位哈希00110,对应于6号桶;高8位10010111,十进制为151,由于桶中前6个cell已经有正常哈希值填充了(遍历),所以将151对应的高位哈希值放置于第7位cell,对应将key和value分别置于相应的第七个空位。
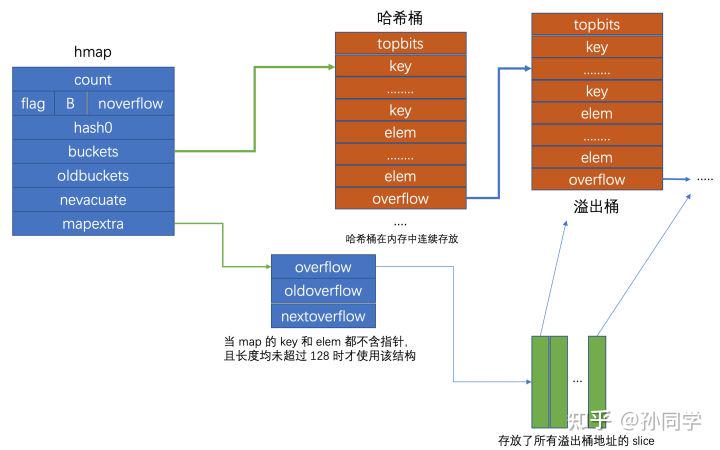
# 1.3.1.5 数据结构
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/gc/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
- 其中
count字段记录了map目前的元素数目, 当使用len()函数获取map长度时, 返回的便是count成员的值, 因此len()函数作用于map结构时, 其时间复杂度为O(1); flag字段标志map的状态, 如map当前正在被遍历或正在被写入;B是哈希桶数目以2为底的对数, 在go map中, 哈希桶的数目都是2的整数次幂;noverflow是溢出桶的数目, 这个数值不是恒定精确的, 当其 B>=16 时为近似值hash0是随机哈希种子, map创建时调用fastrand函数生成的随机数, 设置的目的是为了降低哈希冲突的概率;buckets是指向当前哈希桶的指针,oldbuckets是当桶扩容时指向旧桶的指针;nevacuate是当桶进行调整时指示的搬迁进度, 小于此地址的buckets是以前搬迁完毕的哈希桶;mapextra则是表征溢出桶的变量;
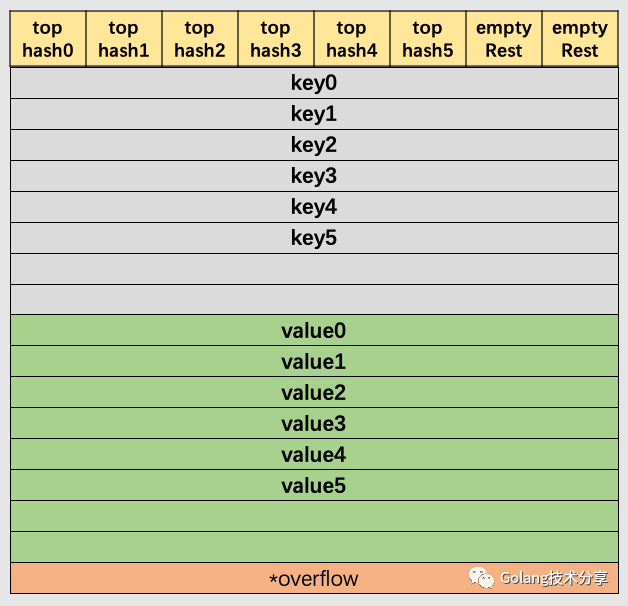
我们先来看bmap, 即哈希桶的结构, 由于go map的key和elem可以有多种数据类型, 因此哈希桶的数据类型也会随着key和elem数据类型的不同而不同, 具体的数据类型是在编译期确定的。
type bmap struct {
topbits [8]uint8
keys [8]keytype
elems [8]elemtype
overflow uintptr
}
2
3
4
5
6
bmap是go map哈希桶的结构, 其中:
topbits是键哈希值的高 8 位keys存放了哈希桶中所有键elems存放了哈希桶中的所有值,overflow是一个uintptr类型指针, 存放了所指向的溢出桶的地址
go map的每个哈希桶最多存放8个键值对, 当经由哈希函数映射到该地址的元素数超过8个时, 会将新的元素放到溢出桶中, 并使用overflow指针链向这个溢出桶。
这里有一个需要注意的点是在哈希桶中, 键值之间并不是相邻排列的, 这是为了保证内存对齐
bmap也就是bucket(桶)的内存模型图解如下:
Go 的 map 结构可以用如下所示的结构图来表示:
# 1.3.2 Map扩容
# 1.3.2.1 扩容的目的
随着向HashTable中插入的元素越来越多, 哈希桶的cell逐渐被填满, 溢出桶的数量可能也越来越多, 此时哈希冲突发生的频率越来越高, key的查询逐步链化, 时间复杂度从o(1)逐步变为o(n),HashTable的性能将不断下降, 为了解决这个问题, 此时需要对HashTable做扩容操作。
# 1.3.2.2 扩容的原则
提到装载因子是决定哈希表是否进行扩容的关键指标。在go的map扩容中,除了装载因子会决定是否需要扩容,溢出桶的数量也是扩容的另一关键指标。
装载因子(负载因子) 判断已经达到装载因子的临界点,即元素个数 >= 桶(bucket)总数 * 6.5,这时候说明大部分的桶可能都快满了(即平均每个桶存储的键值对达到6.5个),如果插入新元素,有大概率需要挂在溢出桶(overflow bucket)上。
负载因子是衡量hash表中当前空间占用率的指标。在go中,就是平均每个bucket存储的元素个数。计算公式如下:
LoadFactor(负载因子)= hash表中已存储的键值对的总数量/hash桶的个数1溢出桶数量 判断溢出桶是否太多,当桶总数 < 2 ^ 15 时,如果溢出桶总数 >= 桶总数,则认为溢出桶过多。当桶总数 >= 2 ^ 15 时,直接与 2 ^ 15 比较,当溢出桶总数 >= 2 ^ 15 时,即认为溢出桶太多了。
# 1.3.2.3 map扩容的方式
- 增量扩容 将 B + 1,新建一个buckets数组,新的buckets大小是原来的2倍,然后旧buckets数据搬迁到新的buckets。
- 等量扩容 buckets数量维持不变,重新做一遍类似增量扩容的搬迁动作,把松散的键值对重新排列一次,以使bucket的使用率更高,进而保证更快的存取。
对于等量扩容而言,由于buckets的数量不变,因此可以按照序号来搬迁。例如老的的0号bucket,仍然搬至新的0号bucket中。
 但是,对于增量扩容而言,就会有所不同。例如原来的B=5,那么增量扩容时,B就会变成6。那么决定key值落入哪个bucket的低位哈希值就会发生变化(从取5位变为取6位),取新的低位hash值得过程称为rehash(重新Hash)。
但是,对于增量扩容而言,就会有所不同。例如原来的B=5,那么增量扩容时,B就会变成6。那么决定key值落入哪个bucket的低位哈希值就会发生变化(从取5位变为取6位),取新的低位hash值得过程称为rehash(重新Hash)。
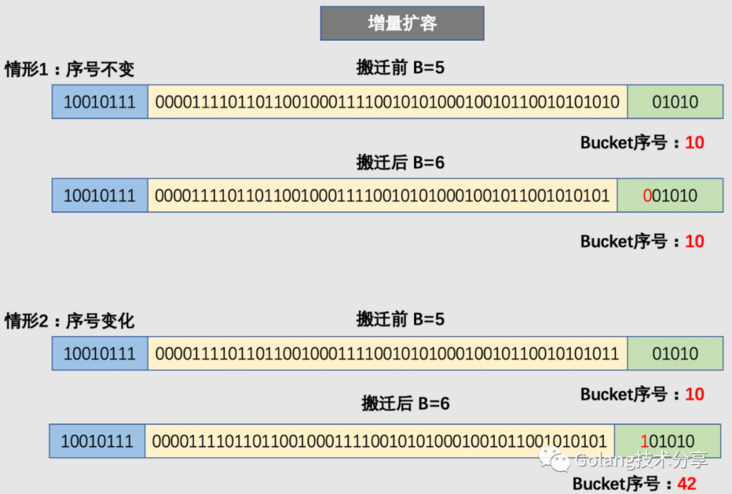 因此,在增量扩容中,某个 key 在搬迁前后 bucket 序号可能和原来相等,也可能是相比原来加上 2^B(原来的 B 值),取决于低 hash 值第倒数第B+1位是 0 还是 1。
因此,在增量扩容中,某个 key 在搬迁前后 bucket 序号可能和原来相等,也可能是相比原来加上 2^B(原来的 B 值),取决于低 hash 值第倒数第B+1位是 0 还是 1。
扩容过程是渐进性的,主要是防止一次扩容需要搬迁的key数量过多,引发性能问题。触发扩容的时机是增加了新元素, 桶搬迁的时机则发生在赋值、删除期间,每次最多搬迁两个桶。
go为了保证遍历map的结果是无序的,做了以下事情:map在遍历时,并不是从固定的0号bucket开始遍历的,每次遍历,都会从一个随机值序号的bucket,再从其中随机的cell开始遍历。然后再按照桶序遍历下去,直到回到起始桶结束。
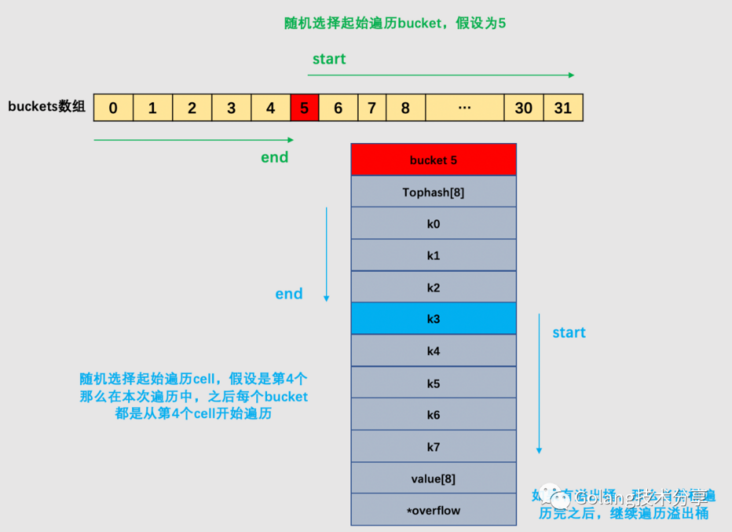
上图的例子,是遍历一个处于未扩容状态的map。如果map正处于扩容状态时,需要先判断当前遍历bucket是否已经完成搬迁,如果数据还在老的bucket,那么就去老bucket中拿数据。
# 1.3.1 Map总结
- Map并不是一个并发安全的数据结构。同时对map进行读写时,程序很容易出错。因此,要想在并发情况下使用map,请加上锁(sync.Mutex或者sync.RwMutex)
- 遍历map的结果是无序的。
- 通过map的结构体可以知道,它其实是通过指针指向底层buckets数组。所以和slice一样,尽管go函数都是值传递,但是,当map作为参数被函数调用时,在函数内部对map的操作同样会影响到外部的map。
# 1.3.2 Sync.Map实现原理
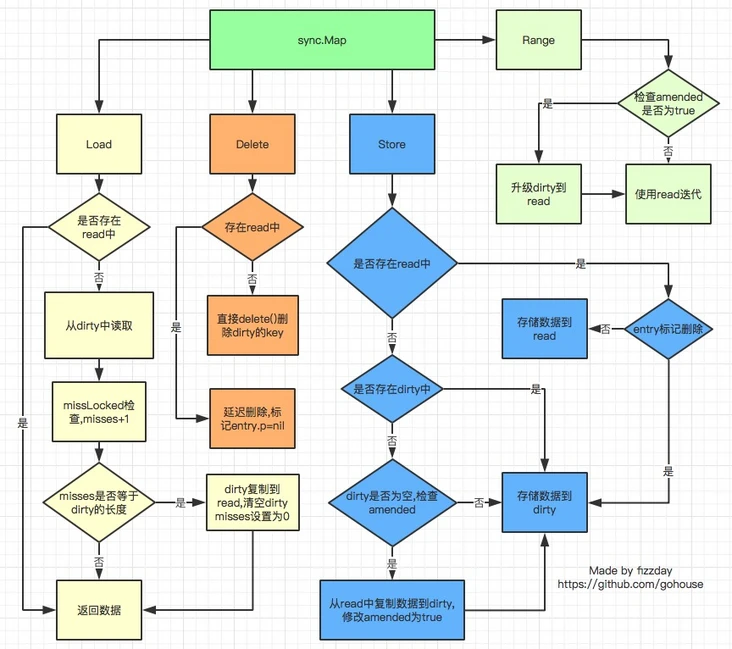
sync.Map的实现原理可概括为:
- 通过read和dirty两个字段将读写分离,读的数据存在只读字段read上,将最新写入的数据则存在dirty字段上;
- 读取时会先查询read,不存在再查询dirty,写入时则只写入dirty;
- 读取read并不需要加锁,而读或写dirty都需要加锁;
- 另外有misses字段来统计read被穿透的次数(被穿透指需要读dirty的情况), 超过一定次数则将dirty数据同步到read上;
- 对于删除数据则直接通过标记来延迟删除.
# 1.3.2.1 总结
- 空间换时间。 通过冗余的两个数据结构(read、dirty),实现加锁对性能的影响。
- 使用只读数据(read),避免读写冲突。
- 动态调整,miss次数多了之后,将dirty数据提升为read。
- double-checking。
- 延迟删除。 删除一个键值只是打标记(会将key对应value的pointer置为nil,但read中仍然有这个key:key;value:nil的键值对),只有在提升dirty的时候才清理删除的数据。
- 优先从read读取、更新、删除,因为对read的读取不需要锁。
- 虽然read和dirty有冗余数据,但这些数据是通过指针指向同一个数据,所以尽管Map的value会很大,但是冗余的空间占用还是有限的。
# 1.3.3 实现有序map
无序的map就是hash map,有序的map一般用红黑树来实现。
# 1.4 Struct
# 1.4.1 空struct使用场景
struct{}本身不占任何空间,可以避免任何多余的内存分配- 有时候给通道发送一个空结构体,
channel<-struct{}{},也是节省了空间 - 仅有方法的结构体
使用示例:
- 将 map 作为集合(Set)使用时,可以将值类型定义为空结构体,仅作为占位符使用即可。
type Set map[string]struct{}
func (s Set) Has(key string) bool {
_, ok := s[key]
return ok
}
func (s Set) Add(key string) {
s[key] = struct{}{}
}
func (s Set) Delete(key string) {
delete(s, key)
}
func main() {
s := make(Set)
s.Add("Tom")
s.Add("Sam")
fmt.Println(s.Has("Tom"))
fmt.Println(s.Has("Jack"))
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
- 不发送数据的信道(channel) 使用 channel 不需要发送任何的数据,只用来通知子协程(goroutine)执行任务,或只用来控制协程并发度。
func worker(ch chan struct{}) {
<-ch
fmt.Println("do something")
close(ch)
}
func main() {
ch := make(chan struct{})
go worker(ch)
ch <- struct{}{}
}
2
3
4
5
6
7
8
9
10
11
- 结构体只包含方法,不包含任何的字段
type Door struct{}
func (d Door) Open() {
fmt.Println("Open the door")
}
func (d Door) Close() {
fmt.Println("Close the door")
}
2
3
4
5
6
7
8
9
# 1.5.2 结构体和结构体指针的区别
- 值结构体在函数的传递过程中,会复制一份,所以其他函数修改后,不会影响到最初初始化的结构体。
- 指针结构体在函数的传递过程中,会复制一份地址进行传递,该地址仍然指向最初的结构体。所以在其他函数修改后,会影响到最初的结构体值。
# 1.5.3 值接收和指针接收的区别
接收者有两种,一种是值接收者,一种是指针接收者。顾名思义,值接收者,是接收者的类型是一个值,是一个副本,方法内部无法对其真正的接收者做更改;指针接收者,接收者的类型是一个指针,是接收者的引用,对这个引用的修改之间影响真正的接收者。
总结:通过指针接收器修改的参数,会影响到结构体的值,修改值接收器的参数,不会影响到结构体的值。
# 1.5.4 深拷贝/浅拷贝
- 浅拷贝:只拷贝对象的第一层属性,如果对象中还有对象,只是拷贝的内存地址(引用),两者修改会相互影响。用于对象中都是基本数据类型的情况。
- 深拷贝:拷贝对象的多层属性,如果对象中还有对象,会继续拷贝,使用递归实现。
- map/channel: 通过make初始化变量,返回一个指针,所以当map、channel作为参数,其实是值传递,但是因为是指针类型,所以函数内的操作会影响到函数外
- slice:通过make初始化,返回slice结构体,slice作为参数传递,struct会通过值传递,将其中的数据拷贝,不过由于slice中的array是一个指针,在操作array的数据时,会影响到函数外的数据(上述操作只是建立在(slice不扩容,函数内的slice没有增删数组)的情况下)
- go中不存在浅拷贝和深拷贝,所有的都是值传递。
# 1.5.5 结构体比较
只有相同类型的结构体才可以比较,结构体是否相同不但与属性类型个数有关,还与属性顺序相关。
Go的结构体有时候并不能直接比较,当其基本类型包含:slice、map、function时,是不能比较的, 编译器会直接报错,如果包含指针,也属于不同的结构体。
type GoodPerson struct {
name string
age int
parent *GoodPerson
d []int
}
func TestStructEquip(t *testing.T) {
p1 := GoodPerson{
name: "h",
age: 1,
}
p2 := GoodPerson{
name: "h",
age: 1,
}
if p1 == p2 {
fmt.Println("相同")
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
结果:
./struct_test.go:50:5: invalid operation: p1 == p2 (struct containing []int cannot be compared)
Compilation finished with exit code 2
2
使用reflect.DeepEqual()进行比较:
type GoodPerson struct {
name string
age int
parent *GoodPerson
}
func TestStructEquip(t *testing.T) {
p1 := GoodPerson{
name: "h",
age: 1,
parent: &GoodPerson{
age: 1,
},
}
p2 := GoodPerson{
name: "h",
age: 1,
parent: &GoodPerson{
age: 1,
},
}
if p1 == p2 {
fmt.Println("相同")
}
if reflect.DeepEqual(p1, p2) {
fmt.Println("相同2")
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
结果:
=== RUN TestStructEquip
相同2
--- PASS: TestStructEquip (0.00s)
PASS
2
3
4
# 1.2 Context
Golang context是Golang应用开发常用的并发控制技术,context翻译成中文是"上下文",即它可以控制一组呈树状结构的goroutine,每个goroutine拥有相同的上下文, 这样context对于派生goroutine有更强的控制力,它可以控制多级的goroutine。
context实际上只定义了接口,凡是实现该接口的类都可称为是一种context,官方包中实现了几个常用的context,分别可用于不同的场景。 context包提供了4个方法创建不同类型的context(用于不同的使用场景),使用这四个方法时如果没有父context,都需要传入backgroud,即backgroud作为其父节点:
- WithCancel()
- WithDeadline()
- WithTimeout()
- WithValue()
总结起就是一句话:context的作用就是在不同的goroutine之间同步请求特定的数据、取消信号以及处理请求的截止日期 (传值、超时、取消)。
# 1.3 闭包
闭包示例:
func f() func() int {
x := 3
return func() int {
x++
return x + 1
}
}
func TestBiBao(t *testing.T) {
_f := f()
fmt.Println(_f())
fmt.Println(_f())
}
2
3
4
5
6
7
8
9
10
11
12
13
结果:
=== RUN TestBiBao
5
6
--- PASS: TestBiBao (0.00s)
PASS
2
3
4
5
总结:
- Go语言支持闭包;
- Go语言能通过escape analyze识别出变量的作用域,自动将变量在堆上分配。将闭包环境变量在堆上分配是Go实现闭包的基础;
- 返回闭包时并不是单纯返回一个函数,而是返回了一个结构体,记录下函数返回地址和引用的环境中的变量地址;
# 2. GMP模型
GPM是Go语言运行时(runtime)层面的实现,是go语言自己实现的一套调度系统。区别于操作系统调度OS线程,其一大特点是goroutine的调度是在用户态下完成的, 不涉及内核态与用户态之间的频繁切换,成本比调度OS线程低很多。 另一方面充分利用了多核的硬件资源,近似的把若干goroutine均分在物理线程上, 再加上本身goroutine的超轻量,以上种种保证了go调度方面的性能。
# 2.1 基础知识
# 2.1.1 GMP的代表含义
- M:Machine,对内核级线程的封装,数量对应真实的CPU数量(真正干活的对象), 一个 M 直接关联了一个内核线程,OS调度器负责把内核线程分配到CPU的核上执行。
- P:Processor,处理器,提供M所需的上下文环境,并且处理用户级代码逻辑的处理器。它负责衔接M和G的调度上下文,将等待执行的G与M对接,其数量可通过GOMAXPROCS来设置,默认是CPU核心数量
- G:Goroutine,协程,相当于轻量级的线程,包括了调用栈,调度信息。
P的数量由环境变量中的GOMAXPROCS决定,通常来说它是和核心数对应,例如在4 Core的服务器上会启动4个线程,通常情况下每个P会负责一个队列。
# 2.1.2 调度流程
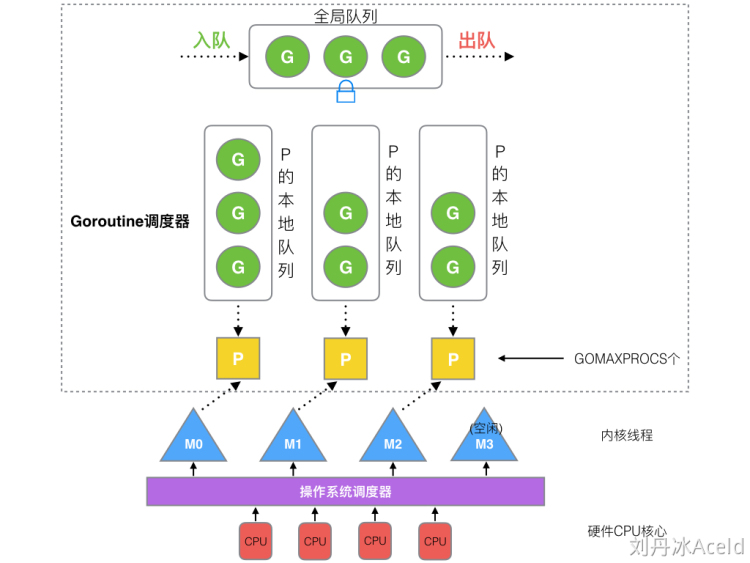
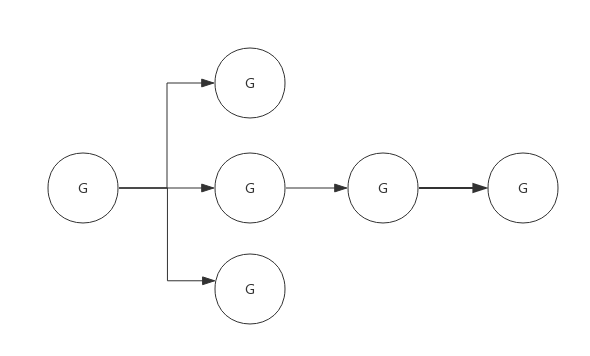
流程如下:
- 每个p有个局部队列,局部队列放的是待执行的goroutine, 存的数量有限,不超过256个, 新建G时,G优先加入到P的本地队列,如果队列满了,则会把本地队列中一半的G移动到全局队列。
- 每个P和一个M绑定,M是真正执行P中goroutine的实体,M从绑定的P的局部队列中获取G来执行
- 当M绑定的P的局部队列为空时,M就会从全局队列获取到本地队列来执行,当全局队列也为空时,M就会从其它P队列偷取G来执行,这种从其它P偷的方式称之为
work stealing - 当G因系统调用(syscall)阻塞时会阻塞M,此时P会和M解绑即
hand off,并寻找新的M,如果没有空闲的M就会新建一个M - 当G因channel或者network I/O操作阻塞时,不会阻塞M,M会寻找其它runable的G,当阻塞的G恢复后重新进入runable进入P队列等待执行
# 2.1.3 G0和M0
- M0是启动程序后的编号为0的主线程,这个M对应的实例会在全局变量runtime.m0中,不需要在heap上分配,M0负责执行初始化操作和启动第一个G, 在之后M0就和其他的M一样了。
- G0是每次启动一个M都会第一个创建的gourtine,G0仅用于负责调度的G,G0不指向任何可执行的函数, 每个M都会有一个自己的G0。在调度或系统调用时会使用G0的栈空间, 全局变量的G0是M0的G0。
# 2.1.4 P/M数量限制
- P的数量限制:由启动时环境变量
$GOMAXPROCS或者是由runtime的方法GOMAXPROCS()决定。这意味着在程序执行的任意时刻都只有$GOMAXPROCS个goroutine在同时运行。 - M的数量:
- go语言本身的限制:go程序启动时,会设置M的最大数量,默认10000.但是内核很难支持这么多的线程数,所以这个限制可以忽略。
- runtime/debug中的
SetMaxThreads函数,设置M的最大数量 - 一个M阻塞了,会创建新的M。
M与P的数量没有绝对关系,一个M阻塞,P就会去创建或者切换另一个M,所以,即使P的默认数量是1,也有可能会创建很多个M出来。
# 2.1.5 P和M何时会被创建
- P何时创建:在确定了P的最大数量n后,运行时系统会根据这个数量创建n个P(即一开始就创建了N个P)。
- M何时创建:没有足够的M来关联P并运行其中的可运行的G。比如所有的M此时都阻塞住了,而P中还有很多就绪任务,就会去寻找空闲的M,而没有空闲的,就会去创建新的M。
# 2.1.6 调度器的设计策略
# 2.1.6.1 复用线程
复用线程:避免频繁的创建、销毁线程,而是对线程的复用。
work stealing机制: 当本线程无可运行的G时,尝试从其他线程绑定的P偷取G,而不是销毁线程。hand off机制: 当本线程因为G进行系统调用阻塞时,线程释放绑定的P,把P转移给其他空闲的线程执行。
# 2.1.6.2 利用并行
利用并行:GOMAXPROCS设置P的数量,最多有GOMAXPROCS个线程分布在多个CPU上同时运行。GOMAXPROCS也限制了并发的程度,比如GOMAXPROCS = 核数/2,则最多利用了一半的CPU核进行并行。
# 2.1.6.3 抢占试调度
抢占:在coroutine中要等待一个协程主动让出CPU才执行下一个协程,在Go中,一个goroutine最多占用CPU 10ms,防止其他goroutine被饿死,这就是goroutine不同于coroutine的一个地方。
# 2.1.7 GMP调度过程中存在哪些阻塞
- 系统调用system call
- I/O
- channel阻塞
- 锁等待
# 2.1.8 Sysmon
Go Runtime 在启动程序的时候,会创建一个独立的 M 作为监控线程,称为sysmon,它是一个系统级的daemon线程。这个sysmon独立于GPM之外,也就是说不需要P就可以运行,因此官方工具 go tool trace 是无法追踪分析到此线程。
在程序执行期间sysmon每隔20us~10ms轮询执行一次,监控那些长时间运行的 G 任务, 然后设置其可以被强占的标识符,这样别的 Goroutine 就可以抢先进来执行。
# 2.1.8.1 sysmon工作职责
在GPM模型中,我们知道当一个G由于网络请求或系统调用sysycall导致运行阻塞时,go runtime scheduler会对其进行调度,把阻塞G切换出去,再拿一个新的G继续执行,始终让P处于全部执行状态。
那么切换出去的G什么时候再回来继续执行呢?这就是本文要讲的sysmon监控线程。
# 2.1.8.1.1 网络轮询器监控
在GPM模型中当网络请求导致的运行阻塞时,调度器会让当前阻塞的G放入网络轮询器(NetPoller)中,由网络轮询器处理异步网络系统调用,从而让出 P 执行其它goroutine。当异步网络调用由网络轮询器完成后,再由sysmon监控线程将其切换回来继续执行。
sysmon监控线程会每隔20us~10ms轮询一次检查当前网络轮询器中的所有G距离runtime.netpoll被调用是否超过了10ms,如果是则说明当前G执行太久了,则将其放入全局运行队列,等待下一次的继续执行。
# 2.1.8.1.2 系统调用syscall监控
如果是系统调用导致阻塞的话(P的状态为_Psyscall),则会让GM一起切换出去,让P重新找一个GM运行。
syscall 主要通过调用retake()函数,抢占长时间处于_Psyscall状态的P。
除此之外还有由于原子、互斥量或通道操作调用导致 Goroutine 阻塞或直接调用 sleep 导致的阻塞也会导致调度器对G进行切换。
# 2.1.8.1.3 垃圾回收
如果垃圾回收器超过两分钟没有执行的话,sysmon 监控线程也会强制进行GC。
# 2.1.8.2 总结
sysmon也叫监控线程,变动的周期性检查, 有如下作用:
- 释放超过5分钟的span物理内存
- 如果超过两分钟没有垃圾回收,强制执行
- 将长时间未处理的netpoll加入到全局队列
- 向长时间运行的g任务发出抢占调度(超过10ms的g,会进行retake)
# 2.2 runtime常用函数
runtime.Goexit():调用此函数会立即使当前的goroutine的运行终止,而其它的goroutine并不会受此影响。runtime.Goexit在终止当前goroutine前会先执行此goroutine的还未执行的defer语句。请注意千万别在主函数调用runtime.Goexit,因为会引发panic。runtime.Gosched():用于让出CPU时间片,让出当前goroutine的执行权限,调度器安排其它等待的任务运行,并在下次某个时候从该位置恢复执行。这就像跑接力赛,A跑了一会碰到代码runtime.Gosched()就把接力棒交给B了,A歇着了,B继续跑。runtime.NumGoroutine():用来设置可以并行计算的CPU核数最大值,并返回之前的值。
# 3. 内存
# 3.1 GC回收机制
# 3.1.1 常见的垃圾回收算法
常见的垃圾回收算法有以下几种:
# 3.1.1.1 引用计数
对每个对象维护一个引用计数,当引用该对象的对象被销毁时,引用计数减1,当引用计数器为0时回收该对象。
- 优点:对象可以很快的被回收,不会出现内存耗尽或达到某个阀值时才回收。
- 缺点:不能很好的处理循环引用,而且实时维护引用计数,有也一定的代价。
- 代表语言:Python、PHP
# 3.1.1.2 标记-清除
从根变量开始遍历所有引用的对象,引用的对象标记为"被引用",没有被标记的进行回收。
- 优点:解决了引用计数的缺点。
- 缺点:需要STW(Stop The World),即要暂时停掉程序运行。
- 代表语言:Golang(其采用三色标记法)
# 3.1.1.3 分代收集:
按照对象生命周期长短划分不同的代空间,生命周期长的放入老年代,而短的放入新生代,不同代有不同的回收算法和回收频率。
- 优点:回收性能好
- 缺点:算法复杂
- 代表语言: JAVA
# 3.1.2 v1.3 标记清除(mark and sweep)
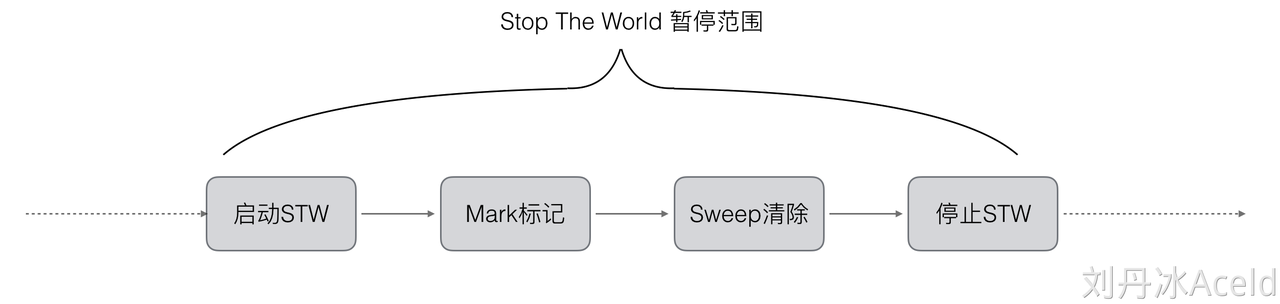
第一步,暂停程序业务逻辑, 分类出可达和不可达的对象,然后做上标记。 第二步, 开始标记,程序找出它所有可达的对象,并做上标记。 第三步, 标记完了之后,然后开始清除未标记的对象; 第四步, 停止暂停,让程序继续跑。然后循环重复这个过程,直到process程序生命周期结束。
操作非常简单,但是有一点需要额外注意:mark and sweep 算法在执行的时候,需要程序暂停!即 STW(stop the world),STW的过程中,CPU不执行用户代码,全部用于垃圾回收,这个过程的影响很大,所以STW也是一些回收机制最大的难题和希望优化的点。所以在执行第三步的这段时间,程序会暂定停止任何工作,卡在那等待回收执行完毕。
# 3.1.2.1 标记清除算法的缺点
标记清除算法明了,过程鲜明干脆,但是也有非常严重的问题。
- STW,stop the world;让程序暂停,程序出现卡顿 (重要问题);
- 标记需要扫描整个heap;
- 清除数据会产生heap碎片。
# 3.1.3 v1.5 三色标记法
三色标记主要是解决之前标记慢的问题。
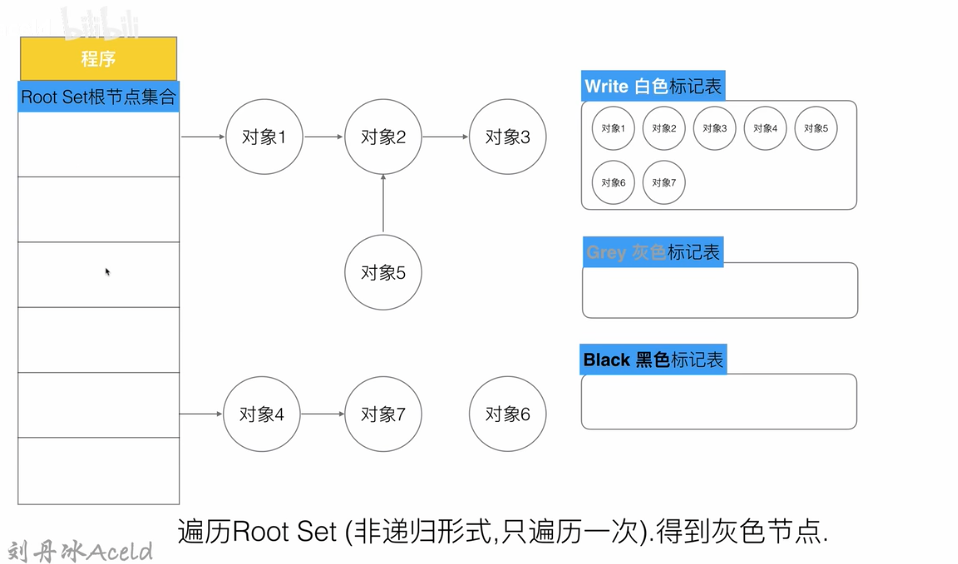
# 3.1.3.1 工作原理
第一步 , 每次新创建的对象,默认的颜色都是标记为“白色”, 第二步, 每次GC回收开始, 会从根节点开始遍历所有对象,把遍历到的对象从白色集合放入“灰色”集合 第三步, 遍历灰色集合,将灰色对象引用的对象从白色集合放入灰色集合,之后将此灰色对象放入黑色集合, 第四步, 重复第三步, 直到灰色中无任何对象, 当我们全部的可达对象都遍历完后,灰色标记表将不再存在灰色对象,目前全部内存的数据只有两种颜色,黑色和白色。那么黑色对象就是我们程序逻辑可达(需要的)对象,这些数据是目前支撑程序正常业务运行的,是合法的有用数据,不可删除,白色的对象是全部不可达对象,目前程序逻辑并不依赖他们,那么白色对象就是内存中目前的垃圾数据,需要被清除。 第五步: 回收所有的白色标记表的对象. 也就是回收垃圾
# 3.1.3.2 缺点
以上便是三色并发标记法,不难看出,我们上面已经清楚的体现三色的特性。但是这里面可能会有很多并发流程均会被扫描,执行并发流程的内存可能相互依赖,为了在GC过程中保证数据的安全,我们在开始三色标记之前就会加上STW,在扫描确定黑白对象之后再放开STW。但是很明显这样的GC扫描的性能实在是太低了。
- STW的问题依然存在
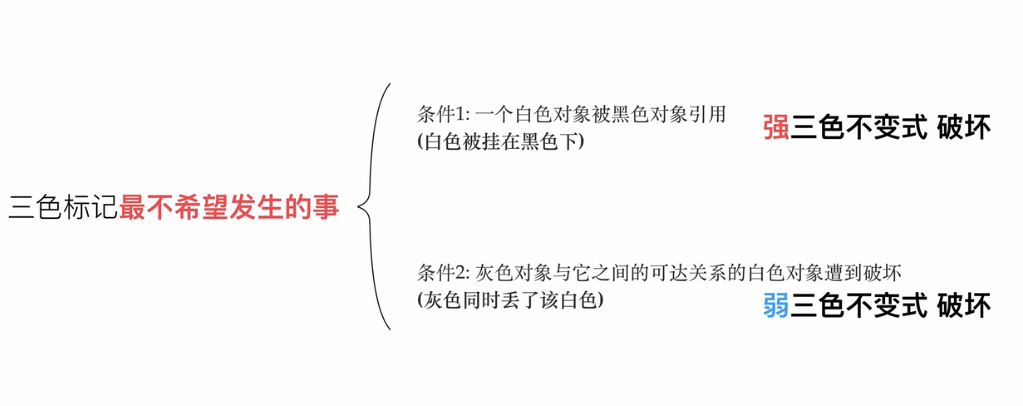
假设三个标记法,不会STW保护,则会出现对象丢失;
 强三色不变式:强制性的不允许黑色对象引用白色对象。(破坏条件1)
弱三色不变式:黑色可以引用白色对象,白色对象存在其他灰色对象对它的引用,或者可达它的链路上游存在灰色对象。(破坏条件2)
强三色不变式:强制性的不允许黑色对象引用白色对象。(破坏条件1)
弱三色不变式:黑色可以引用白色对象,白色对象存在其他灰色对象对它的引用,或者可达它的链路上游存在灰色对象。(破坏条件2)
# 3.1.3.1 强三色不变式
强制不允许黑色对象引用白色对象;

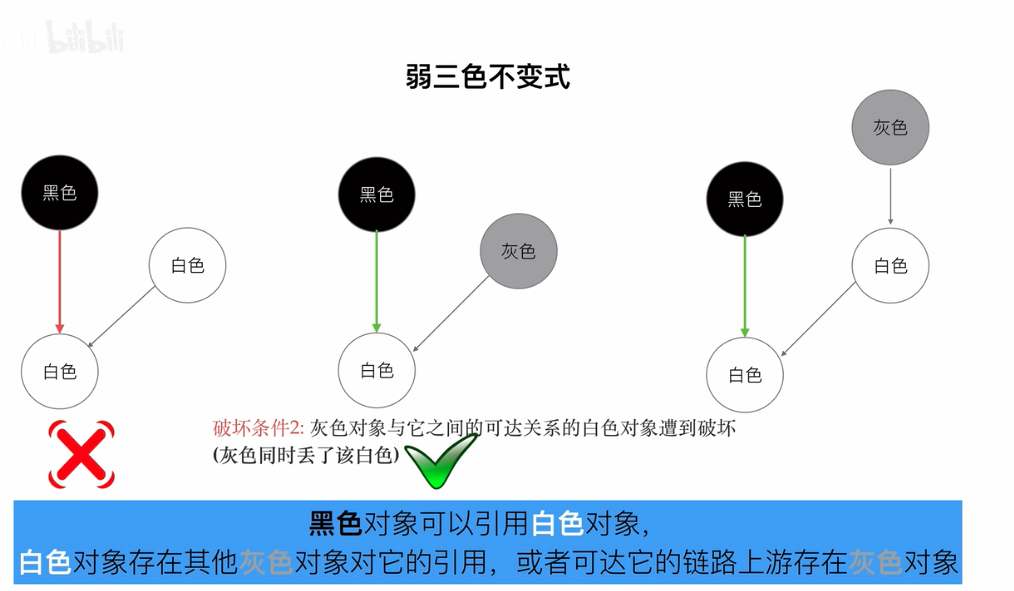
# 3.1.3.2 弱三色不变式
黑色对象可以引用白色对象,但是有个前提,以下情况比如满足其一:
- 白色对象被灰色对象引用;
- 白色对象可达引用链上有灰色对象;
# 3.1.4 v1.8混合写屏障
引入混合写入屏障,实现强三色和弱三色问题,即可动态实现GC,不使用STW.
屏障是指在程序执行过程,增加额外判断机制,类似于hook.
屏障分两种,插入屏障和删除屏障。
- 插入屏障:对象被引用时触发的机制
- 删除屏障:对象被删除时,触发的机制
# 3.1.4.1 插入屏障
对象被引用时触发的屏障。 当标记和程序是并发执行的,这就会造成一个问题. 在标记过程中,有新的引用产生,可能会导致误清扫. 清扫开始前,标记为黑色的对象引用了一个新申请的对象,它肯定是白色的,而黑色对象不会被再次扫描,那么这个白色对象无法被扫描变成灰色、黑色,它就会最终被清扫,而实际它不应该被清扫. 这就需要用到屏障技术,golang 采用了写屏障,作用就是为了避免这类误清扫问题. 写屏障即在内存写操作前,维护一个约束,从而确保清扫开始前,黑色的对象不能引用白色对象.
- 在A对象引用B对象时,不管B对象什么颜色,都标记为灰色。

- 为了保障栈的效率,栈上的对象不执行插入屏障
为了避免栈出现对象丢失,在准备回收白色对象前,启动STW,扫描栈空间,重新对栈上的对象进行标记)
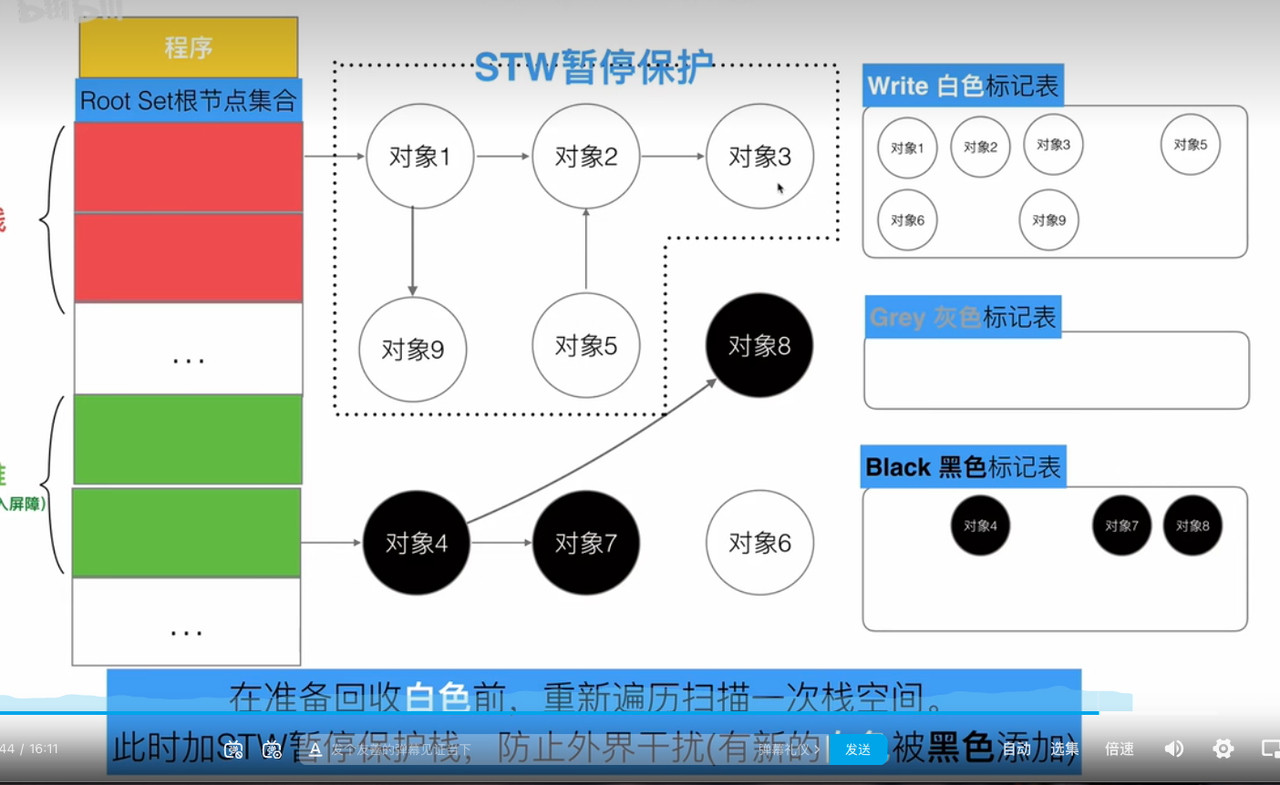
这样减少了STW的执行时间(栈空间大小有限,所以存储的对象也不多)。
# 3.1.4.1.1 插入写屏障的不足
- 结束时需要STW来重新扫描栈

# 3.1.4.2 删除屏障
对象被删除时触发的屏障。
被删除的对象,如果自身是灰色或者白色,都标记为灰色,满足弱三色不变式,保障灰色到白色对象的路径不会断。保护对象会被延迟一轮被删除。
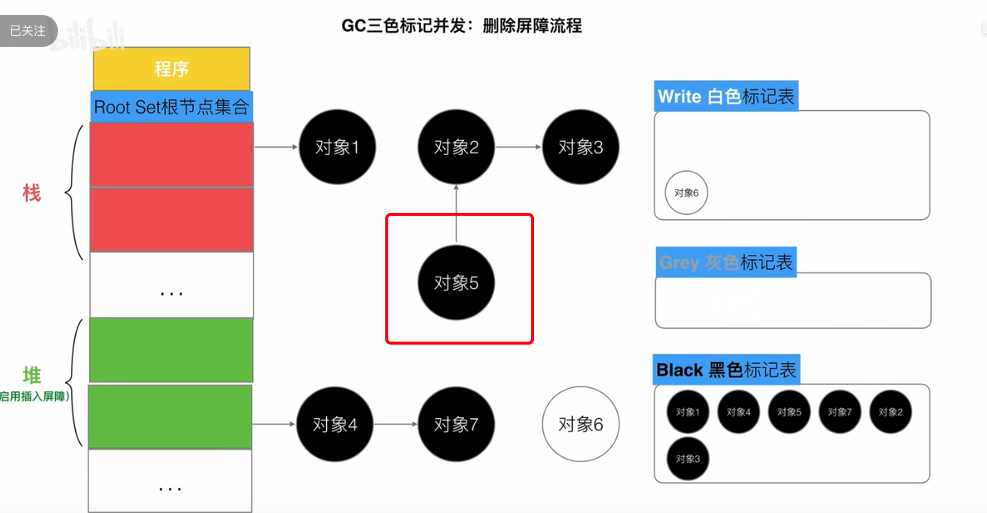

# 3.1.4.3 混合写屏障

# 3.1.4.4 插入写屏障与删除写屏障的缺点
- 插入写屏障:结束时需要STW来重新扫描栈,标记栈上引用的白色对象的存活。仅适用于堆(程序运行基本在栈中,存在大量变量声明、赋值及函数调用,若栈中使用插入写屏障,将极大增加复杂度、降低性能)
- 删除写屏障:回收精度低,GC开始时STW扫描堆栈来记录初始快照,这个过程会保护开始时刻的所有存活对象。仅适用于堆
# 3.1.5 GC时机
内存分配量达到阀值:触发GC每次内存分配时,都会检查当前内存分配量是否已达到阀值,如果达到阀值则立即启动GC:- 阀值 = 上次 GC 内存分配量 * 内存增长率
- 内存增长率由环境变量 GOGC控制,默认为100,即每当内存扩大一倍时启动GC
定期触发GC:默认情况下,最长2分钟,由sysmon触发一次GC,这个间隔在src/runtime/proc.go:forcegcperiod变量中被声明手动触发:程序代码中也可以使用runtime.GC()来手动触发GC。这主要用于GC性能测试和统计。
# 3.1.6 GC调优
# 3.1.6.1 分析GC方法
- GODEBUG='gctrace=1'
package main
func main() {
for n := 1; n < 100000; n++ {
_ = make([]byte, 1<<20)
}
}
$ GODEBUG='gctrace=1' go run main.go
2
3
4
5
6
7
8
- go tool trace
package main
import (
"os"
"runtime/trace"
)
func main() {
f, _ := os.Create("trace.out")
defer f.Close()
trace.Start(f)
defer trace.Stop()
for n := 1; n < 100000; n++ {
_ = make([]byte, 1<<20)
}
}
// go run main.go
// go tool trace trace.out
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
- debug.ReadGCStats
package main
import (
"fmt"
"runtime/debug"
"time"
)
func printGCStats() {
t := time.NewTicker(time.Second)
s := debug.GCStats{}
for {
select {
case <-t.C:
debug.ReadGCStats(&s)
fmt.Printf("gc %d last@%v, PauseTotal %v\n", s.NumGC, s.LastGC, s.PauseTotal)
}
}
}
func main() {
go printGCStats()
for n := 1; n < 100000; n++ {
_ = make([]byte, 1<<20)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
- runtime.ReadMemStats
package main
import (
"fmt"
"runtime"
"time"
)
func printMemStats() {
t := time.NewTicker(time.Second)
s := runtime.MemStats{}
for {
select {
case <-t.C:
runtime.ReadMemStats(&s)
fmt.Printf("gc %d last@%v, heap_object_num: %v, heap_alloc: %vMB, next_heap_size: %vMB\n",
s.NumGC, time.Unix(int64(time.Duration(s.LastGC).Seconds()), 0), s.HeapObjects, s.HeapAlloc/(1<<20), s.NextGC/(1<<20))
}
}
}
func main() {
go printMemStats()
fmt.Println(1 << 20)
for n := 1; n < 100000; n++ {
_ = make([]byte, 1<<20)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 3.1.6.2 调优
GC调优,通常是指减少用户代码对GC产生的压力,这一方面包含了减少用户代码分配内存的数量(即对程序的代码行为进行调优),另一方面包含了最小化Go的GC对CPU的使用率(即调整 GOGC)。
GC的调优是在特定场景下产生的,并非所有程序都需要针对GC进行调优。只有那些对执行延迟非常敏感、当GC的开销成为程序性能瓶颈的程序,才需要针对GC进行性能调优,几乎不存在于实际开发中 99% 的情况。
总的来说,我们可以在现在的开发中处理的有以下几种情况:
- 对停顿敏感:GC过程中产生的长时间停顿、或由于需要执行GC而没有执行用户代码,导致需要立即执行的用户代码执行滞后。
- 对资源消耗敏感:对于频繁分配内存的应用而言,频繁分配内存增加GC的工作量,原本可以充分利用CPU的应用不得不频繁地执行垃圾回收,影响用户代码对CPU的利用率,进而影响用户代码的执行效率。
从这两点来看,所谓GC调优的核心思想也就是充分的围绕上面的两点来展开:优化内存的申请速度,尽可能的少申请内存,复用已申请的内存。或者简单来说,不外乎这三个关键字:控制、减少、复用。
GC优化一般有如下方法:
- 控制内存分配的速度,小对象过多会导致GC三色法消耗过多的GPU, 限制 goroutine 的数量,从而提高赋值器对 CPU 的利用率。
- 减少并复用内存,例如使用
sync.Pool来复用需要频繁创建临时对象,例如提前分配足够的内存来降低多余的拷贝。 - 需要时,增大
GOGC的值,降低GC的运行频率。
golang gc调整的方案大概如下:
debug.SetGCPercent(1000) //默认值是100, 大概逻辑是,当前内存使用达到上次gc后内存使用的2倍左右(假如按默认值100来说),即开始新一轮gc
debug.SetMaxHeap(10G) (按上限设)
2
// 大概逻辑是,当前内存使用达到10G后开始新一轮gc
notify := make(chan struct{}, 1)
debug.SetMaxHeap(10<<30, notify) // 设置阈值为10GB
debug.SetGCPercent(-1) // 关闭按比例GC
2
3
4
# 3.2 逃逸分析
Go和C++不同,Go局部变量会进行逃逸分析。如果变量离开作用域后没有被引用,则优先分配到栈上,否则分配到堆上。那么如何判断是否发生了逃逸呢?
go build -gcflags '-m -l' mem_taoyi.go
# command-line-arguments
./mem_taoyi.go:11:13: ... argument does not escape
./mem_taoyi.go:11:13: s escapes to heap
2
3
4
# 3.2.1 逃逸的可能情况
逃逸分析是一种确定指针动态范围的方法,编译器会在编译阶段对代码进行分析,当发现当前作用域的变量没有跨出函数范围,则会自动分配在stack上,反之则分配在heap上。如果栈上分配的内存过大(是否逃逸取决于栈空间是否足够大),则会分配到堆上, 记住, 是在编译阶段确立逃逸,并不是在运行时。
func sum(a, b int) int {
m := make(map[string]int)
m["name"] = 1
return a + b + len(m)
}
func main() {
s := sum(1, 2)
s++
runtime.NumGoroutine()
runtime.GOMAXPROCS(1)
}
2
3
4
5
6
7
8
9
10
11
12
13
go build -gcflags '-m -l' mem_taoyi.go
# command-line-arguments
./mem_taoyi.go:6:11: make(map[string]int) does not escape
2
3
逃逸分析的作用:
- 减少gc的压力,不逃逸的对象(包括map,slice这些)分配在栈上,当函数返回时就回收了资源,不需要gc标记清除, 逃逸到堆上的内存需要GC进行回收;
- 逃逸分析完后可以确定哪些变量可以分配在栈上,栈的分配比堆快,性能好;
关于逃逸的可能情况:
- 指针逃逸:返回函数内的局部变量指针,指针指向内存,所以不能被回收
- 栈空间不足逃逸,即一次性分配了较大的对象,比如make([]int, 0, 10000)
- 动态类型逃逸,很多函数参数为interface类型,编译期间很难确定其参数的具体类型,也能产生逃逸。如下,在有无fmt.Println,打印的结果不同,因为产生了内存逃逸,而在不同的内存中
- 闭包引用对象逃逸
# 3.3 内存泄漏
# 3.3.1 内存泄漏的可能情况
在Go中内存泄露分为暂时性内存泄露和永久性内存泄露。
暂时性内存泄露:
- 获取长字符串中的一段导致长字符串未释放
- 获取长slice中的一段导致长slice未释放
- 在长slice新建slice导致泄漏
- string相比切片少了一个容量的cap字段,可以把string当成一个只读的切片类型。获取长string或者切片中的一段内容,由于新生成的对象和老的string或者切片共用一个内存空间,会导致老的string和切片资源暂时得不到释放,造成短暂的内存泄漏
永久性内存泄露:
- goroutine永久阻塞而导致泄漏
- time.Ticker未关闭导致泄漏
- 不正确使用Finalizer(Go版本的析构函数)导致泄漏
# 3.3.2 常见内存泄漏
- 协程泄漏:协程泄漏是指协程创建之后没有得到释放,主要原因有:
- 缺少接收器,导致发送阻塞
- 缺少发送器,导致接收阻塞
- 死锁。多个协程由于竞争资源导致死锁。
- 创建协程的没有回收。
- waitgroup的Add、Done和wait数量不匹配会导致wait一直在等待
- slice引起的内存泄漏:当两个slice 共享地址,其中一个为全局变量,另一个也无法被GC;
# 3.3.3 内存泄漏的解决办法
针对可能进行泄漏的地方进行排查,可以通过Golang自带的pprof工具进行分析。
# 3.4 内存对齐
CPU访问内存时,并不是逐个字节访问,而是以字长(word size)为单位访问。比如32位的CPU ,字长为4字节,那么CPU访问内存的单位也是4字节。 CPU始终以字长访问内存,如果不进行内存对齐,很可能增加 CPU 访问内存的次数,例如:
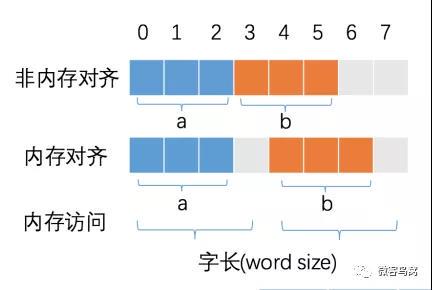
变量a、b各占据3字节的空间,内存对齐后,a、b占据4字节空间,CPU读取b变量的值只需要进行一次内存访问。如果不进行内存对齐,CPU读取b变量的值需要进行2次内存访问。第一次访问得到b变量的第1个字节,第二次访问得到b变量的后两个字节。
也可以看到,内存对齐对实现变量的原子性操作也是有好处的,每次内存访问是原子的,如果变量的大小不超过字长,那么内存对齐后,对该变量的访问就是原子的,这个特性在并发场景下至关重要。
# 3.4.1 什么是内存对齐
为了能让CPU可以更快的存取到各个字段,Go编译器会帮你把struct结构体做数据的对齐。所谓的数据对齐,是指内存地址是所存储数据大小(按字节为单位)的整数倍,以便CPU可以一次将该数据从内存中读取出来。 编译器通过在结构体的各个字段之间填充一些空白已达到对齐的目的。
# 3.4.2 对齐系数
不同硬件平台占用的大小和对齐值都可能是不一样的,每个特定平台上的编译器都有自己的默认"对齐系数",32位系统对齐系数是4,64位系统对齐系数是8。
不同类型的对齐系数也可能不一样,使用Go语言中的unsafe.Alignof函数可以返回相应类型的对齐系数,对齐系数都符合2^n这个规律,最大也不会超过8
package main
import (
"fmt""unsafe"
)
func main() {
fmt.Printf("bool alignof is %d\n", unsafe.Alignof(bool(true)))
fmt.Printf("string alignof is %d\n", unsafe.Alignof(string("a")))
fmt.Printf("int alignof is %d\n", unsafe.Alignof(int(0)))
fmt.Printf("float alignof is %d\n", unsafe.Alignof(float64(0)))
fmt.Printf("int32 alignof is %d\n", unsafe.Alignof(int32(0)))
fmt.Printf("float32 alignof is %d\n", unsafe.Alignof(float32(0)))
}
2
3
4
5
6
7
8
9
10
11
12
13
14
可以查看到各种类型在Mac 64位上的对齐系数如下:
bool alignof is 1
string alignof is 8
int alignof is 8
int32 alignof is 4
float32 alignof is 4
float alignof is 8
2
3
4
5
6
- 优点
- 提高可移植性,有些CPU可以访问任意地址上的任意数据,而有些CPU只能在特定地址访问数据,因此不同硬件平台具有差异性,这样的代码就不具有移植性,如果在编译时,将分配的内存进行对齐,这就具有平台可以移植性了
- 提高内存的访问效率,32位CPU下一次可以从内存中读取32位(4个字节)的数据,64位CPU下一次可以从内存中读取64位(8个字节)的数据,这个长度也称为CPU的字长。CPU一次可以读取1个字长的数据到内存中,如果所需要读取的数据正好跨了1个字长,那就得花两个CPU周期的时间去读取了。因此在内存中存放数据时进行对齐,可以提高内存访问效率。
- 缺点
- 存在内存空间的浪费,实际上是空间换时间
# 3.4.3 结构体对齐
对齐原则:
- 结构体变量中成员的偏移量必须是成员大小的整数倍
- 整个结构体的地址必须是最大字节的整数倍(结构体的内存占用是1/4/8/16byte...)
package main
import (
"fmt""runtime""unsafe"
)
type T1 struct {
bool bool // 1 byte
i16 int16 // 2 byte
}
type T2 struct {
i8 int8 // 1 byte
i64 int64 // 8 byte
i32 int32 // 4 byte
}
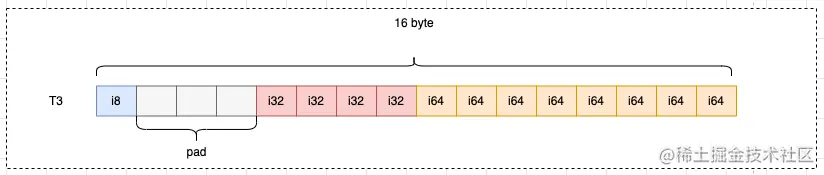
type T3 struct {
i8 int8 // 1 byte
i32 int32 // 4 byte
i64 int64 // 8 byte
}
func main() {
fmt.Println(runtime.GOARCH) // amd64
t1 := T1{}
fmt.Println(unsafe.Sizeof(t1)) // 4 bytes
t2 := T2{}
fmt.Println(unsafe.Sizeof(t2)) // 24 bytes
t3 := T3{}
fmt.Println(unsafe.Sizeof(t3)) // 16 bytes
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
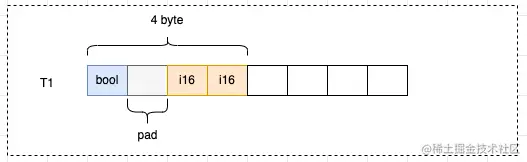
以T1结构体为例,实际存储数据的只有3字节,但实际用了4字节,浪费了1个字节:
i16并没有直接放在bool的后面,而是在bool中填充了一个空白后,放到了偏移量为2的位置上。如果i16从偏移量为1的位置开始占用2个字节,根据对齐原则2:构体变量中成员的偏移量必须是成员大小的整数倍,套用公式 1 % 2 = 1,就不满足对齐的要求,所以i16从偏移量为2的位置开始
 以T2结构体为例,实际存储数据的只有13字节,但实际用了24字节,浪费了11个字节:
以T2结构体为例,实际存储数据的只有13字节,但实际用了24字节,浪费了11个字节:
 以T3结构体为例,实际存储数据的只有13字节,但实际用了16字节,浪费了3个字节:
以T3结构体为例,实际存储数据的只有13字节,但实际用了16字节,浪费了3个字节:
# 3.5 问题
# 3.5.1 make与new的异同
- 相同点:都是为引用类型分配内存空间(不一定在堆上)
- 不同点
- make只适用于slice,map和chanel的初始化;
- new用于类型内存的初始化,返回指向分配类型的内存地址,但是现实的编码中,它是不常用的。我们通常都是采用短语句声明以及结构体的字面量达到我们的目的。
- make返回的还是这三个引用类型本身;而new返回的是指向类型的指针。
// 引用类型初始化一定要分配内存
var i *int
i=new(int)
*i=10
// 直接短语句声明和初始化
u := user{}
2
3
4
5
6
7
# 3.5.2 如何减少小对象分配?
优化工作经常和特定应用程序相关,但也有一些普遍建议:
将小对象组合成大对象。比如, 将 *bytes.Buffer 结构体成员替换为bytes。缓冲区 (你可以预分配然后通过调用bytes.Buffer.Grow为写做准备) 。这将减少很多内存分配(更快)并且减缓垃圾回收器的压力(更快的垃圾回收) 。
离开声明作用域的局部变量促进堆分配。编译器不能保证这些变量拥有相同的生命周期,因此为他们分别分配空间。所以你也可以对局部变量使用上述的建议。比如:将
for k, v := range m { k, v := k, v // copy for capturing by the goroutinego func() { // use k and v }() }1
2
3
4
5替换为:
for k, v := range m { x := struct{ k, v string }{k, v} // copy for capturing by the goroutinego func() { // use x.k and x.v }() }1
2
3
4
5这就将两次内存分配替换为了一次。然而,这样的优化方式会影响代码的可读性,因此要合理地使用它。
组合内存分配的一个特殊情形是分片数组预分配。如果你清楚一个特定的分片的大小,你可以给末尾数组进行预分配:
type X struct { buf []byte bufArray [16]byte // Buf usually does not grow beyond 16 bytes. } func MakeX() *X { x := &X{} // Preinitialize buf with the backing array. x.buf = x.bufArray[:0] return x }1
2
3
4
5
6
7
8
9
10尽可能使用小数据类型。比如用int8代替int。
多个局部变量合并成结构体或数组
使用对象池
# 4 并发
# 4.1 Channel
# 4.1.1 Channel特性
- 给一个
nil channel发送数据,造成永远阻塞 (操作未被初始化的通道会造成永久阻塞) - 从一个
nil channel接收数据,造成永远阻塞 (操作未被初始化的通道会造成永久阻塞) - 给一个已经关闭的
channel发送数据,引起panic - 从一个已经关闭的
channel接收数据,如果缓冲区中为空,则返回一个零值 (发送端关闭通道不会影响接收端接收) - 无缓冲的channel是同步的,而有缓冲的channel是非同步的 , 带缓冲区和不带缓冲区的channel区别就是长度是否为0,不带缓冲区的channel的长度就是0。
# 4.1.2 原理
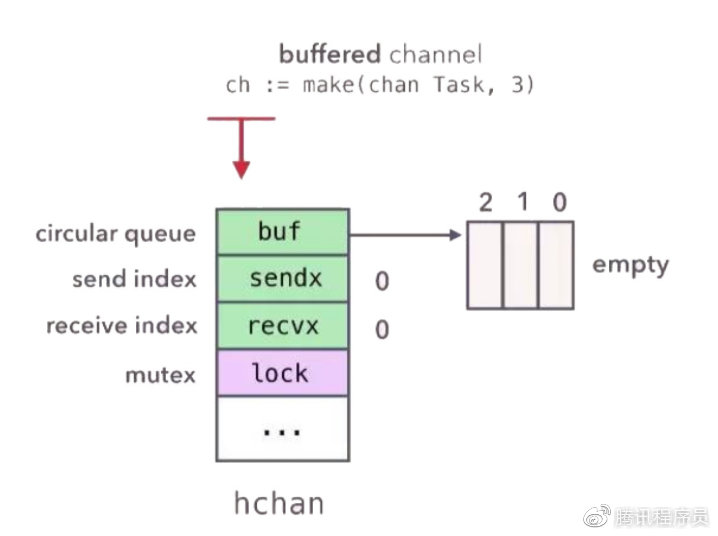
使用一个环形队列来保存groutine之间传递的数据(如果是缓存channel的话),使用两个list保存向该chan发送和从该chan接收数据的goroutine,还有一个mutex来保证操作这些结构的安全。
# 4.1.3 源码分析
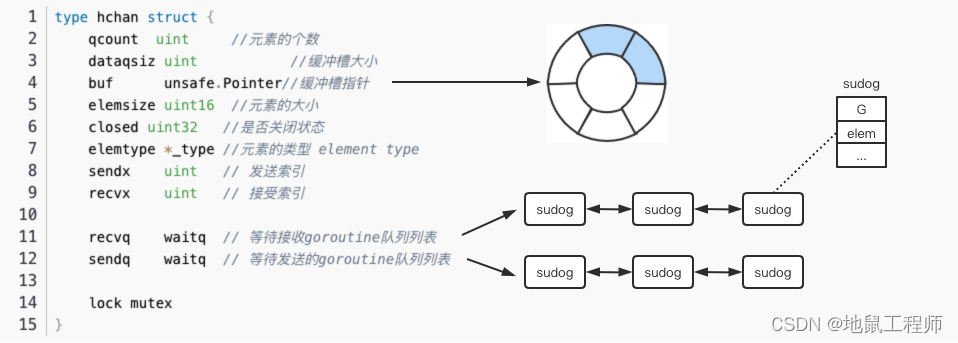
type hchan struct {
qcount uint // 循环列表元素个数
dataqsiz uint // 循环队列的大小
buf unsafe.Pointer // 循环队列的指针
elemsize uint16 // chan中元素的大小
closed uint32 // 是否已close
elemtype *_type // chan中元素类型
sendx uint // send在buffer中的索引
recvx uint // recv在buffer中的索引
recvq waitq // receiver的等待队列
sendq waitq // sender的等待队列
// 互拆锁
lock mutex
}
2
3
4
5
6
7
8
9
10
11
12
13
14
qcount代表chan 中已经接收但还没被取走的元素的个数,函数len可以返回这个字段的值;dataqsiz和buf分别代表队列buffer的大小,cap函数可以返回这个字段的值以及队列buffer的指针,是一个定长的环形数组;elemtype和elemsiz表示chan中元素的类型和元素的大小;sendx:发送数据的指针在buffer中的位置;recvx:接收请求时的指针在buffer中的位置;recvq和sendq分别表示等待接收数据的goroutine与等待发送数据的 goroutine;
sendq和recvq的类型是waitq的结构体:
type waitq struct {
first *sudog
last *sudog
}
2
3
4
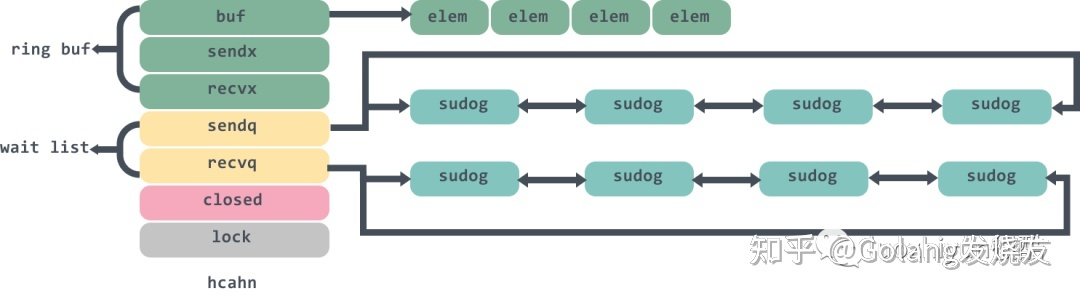
waitq里面连接的是一个sudog双向链表,保存的是等待的goroutine 。整个chan的图例大概是这样:
# 4.1.3.1 发送数据
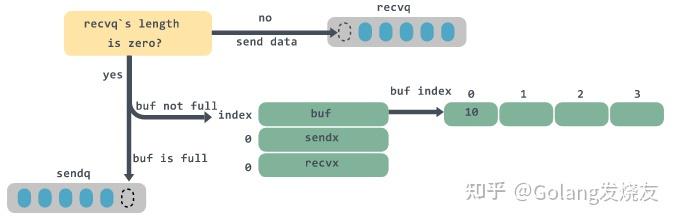
- 检查 recvq 是否为空,如果不为空,则从 recvq 头部取一个 goroutine,将数据发送过去;
- 如果 recvq 为空,,并且buf没有满,则将数据放入到 buf中;
- 如果 buf已满,则将要发送的数据和当前 goroutine 打包成sudog,然后入队到sendq队列中,并将当前 goroutine 置为 waiting 状态进行阻塞。
# 4.1.4 Channel与共享内存的区别
Go 语言中实现了两种并发模型,一种是依赖于共享内存实现的线程-锁并发模型,另一种则是CSP(Communicationing Sequential Processes,通信顺序进程)并发模型。主要是 Go sync 包中的互斥锁、读写锁、条件变量、原子操作等同步原语。后者(CSP模型)目的在于简化并发程序的编写,让并发程序的编写顺序像编写顺序程序一样简单,是 Go 的主流并发模型。
# 4.1.5 Channel的优势和弊端
优点:使用 channel 可以帮助我们解耦生产者和消费者,可以降低并发当中的耦合 缺点:容易出现死锁的情况
# 4.2 waitGroup
# 4.2.1 waitGroup原理概括
waitGroup主要用来阻塞主协程,可以等待所有协程执行完。 WaitGroup 主要维护了 2 个计数器,一个是请求计数器 v,一个是等待计数 器 w,二者组成一个 64bit 的值,请求计数器占高 32bit,等待计数器占低 32bit。 每次 Add 执行,请求计数器 v 加 1,Done 方法执行,等待计数器减 1,v 为 0 时通过信号量唤醒 Wait()。
# 4.2.2 底层数据结构
// A WaitGroup must not be copied after first use.
type WaitGroup struct {
noCopy noCopy
// 64-bit value: high 32 bits are counter, low 32 bits are waiter count.
// 64-bit atomic operations require 64-bit alignment, but 32-bit
// compilers only guarantee that 64-bit fields are 32-bit aligned.
// For this reason on 32 bit architectures we need to check in state()
// if state1 is aligned or not, and dynamically "swap" the field order if
// needed.
state1 uint64
state2 uint32
}
2
3
4
5
6
7
8
9
10
11
12
13
- 其中
noCopy是golang源码中检测禁止拷贝的技术。如果程序中有WaitGroup的赋值行为,使用go vet检查程序时,就会发现有报错。
# 4.2.3 使用方法
在WaitGroup里主要有3个方法:
WaitGroup.Add():可以添加或减少请求的goroutine数量,Add(n) 将会导致 counter += nWaitGroup.Done():相当于Add(-1),Done() 将导致 counter -=1,请求计数器counter为0 时通过信号量调用runtime_Semrelease唤醒waiter线程WaitGroup.Wait():会将 waiter++,同时通过信号量调用 runtime_Semacquire(semap)阻塞当前 goroutine
func main() {
var wg sync.WaitGroup
for i := 1; i <= 5; i++ {
wg.Add(1)
go func() {
defer wg.Done()
println("hello")
}()
}
wg.Wait()
}
2
3
4
5
6
7
8
9
10
11
12
# 4.3 sync.Once
sync.once通过cas和互斥锁实现了程序只执行一次。
// Once is an object that will perform exactly one action.
//
// A Once must not be copied after first use.
type Once struct {
done uint32
m Mutex
}
func (o *Once) Do(f func()) {
if atomic.LoadUint32(&o.done) == 0 {
o.doSlow(f)
}
}
func (o *Once) doSlow(f func()) {
o.m.Lock()
defer o.m.Unlock()
if o.done == 0 {
defer atomic.StoreUint32(&o.done, 1)
f()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 4.4 aotomic
atomic源码位于sync\atomic。通过阅读源码可知,atomic采用CAS(CompareAndSwap)的方式实现的。所谓CAS就是使用了CPU中的原子性操作。在操作共享变量的时候,CAS不需要对其进行加锁,而是通过类似于乐观锁的方式进行检测,总是假设被操作的值未曾改变(即与旧值相等),并一旦确认这个假设的真实性就立即进行值替换。本质上是不断占用CPU资源来避免加锁的开销。
# 4.4.1 CAS
CAS,即Compare and Swap,是基于硬件级别的指令实现的同步原语。处理器(包括 Intel 和 Sparc 处理器)使用的最通用的方法是实现名为比较并转换或CAS的原语,在 Intel 处理器中,比较并交换通过指令的 cmpxchg系列实现。
CAS 操作包含三个操作数 —— 内存位置(V)、预期原值(A)和新值(B)。如果内存位置的值V与预期原值A相匹配,那么处理器会自动将该位置值V更新为新值B,否则,处理器不做任何操作,整个操作保证了原子性,即在对比V==A后、设置V=B之前不会有其他线程修改V的值。
CAS存在的问题:
- 效率问题:前面提到,如果存在多个线程竞争,可能导致CAS失败,此时可能需要循环(自旋)执行CAS,竞争激烈情况下会对性能有一定影响;
- ABA问题:CAS过程中其他线程把变量从A改成B,然后又改回A,CAS判断值没变于是执行更新操作,但事实上值是被修改了的,与设计原语不符,atomic包引入AtomicStampReference类解决ABA问题,每次变量更新的时候,将变量的版本号+1,之前的ABA问题中,变量经过两次操作以后,变量的版本号就会由1变成3,也就是说只要线程对变量进行过操作,变量的版本号就会发生更改,从而解决了ABA问题;但实际应用中ABA问题如果对业务逻辑不会造成影响,可以忽略;
# 4.5 unsafe.Pointer/uintptr
unsafe.Pointer通用指针类型,一种特殊类型的指针,可以包含任意类型的地址,能实现不同的指针类型之间进行转换,类似于C语言里的void*指针。
uintptr是 Go 内置类型,表示无符号整数,可存储一个完整的地址。常用于指针运算,只需将unsafe.Pointer类型转换成uintptr类型,做完加减法后,转换成unsafe.Pointer,通过 * 操作,取值或者修改值都可以。
Go 官方文档对这个类型有如下四个描述:
- 任何类型的指针都可以被转化为
unsafe.Pointer; unsafe.Pointer可以被转化为任何类型的指针;uintptr可以被转化为unsafe.Pointer;unsafe.Pointer可以被转化为uintptr。
type Admin struct {
Name string
Age int
}
func main(){
admin := Admin{
Name: "seekload",
Age: 18,
}
ptr := &admin
// 1 因为结构体初始地址就是第一个成员的地址,又 Name 是结构体第一个成员变量,所以此处不用偏移,我们拿到 admin 的地址,然后通过 unsafe.Pointer 转为 *string,再进行赋值操作即可
name := (*string)(unsafe.Pointer(ptr)) // 1
*name = "四哥"
fmt.Println(*ptr) // 输出:{四哥 18}
// 2 成员变量 Age 不是第一个字段,想要修改它的值就需要内存偏移。我们先将 admin 的指针转化为 uintptr,再通过 unsafe.Offsetof() 获取到 Age 的偏移量,两者都是 uintptr,进行相加指针运算获取到成员 Age 的地址,最后需要将 uintptr 转化为 unsafe.Pointer,再转化为 *int,才能对 Age 操作。
age := (*int)(unsafe.Pointer(uintptr(unsafe.Pointer(ptr)) + unsafe.Offsetof(ptr.Age))) // 2
*age = 35
fmt.Println(*ptr) // 输出:{四哥 35}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
特别提下,unsafe.Offsetof的作用是返回成员变量x在结构体当中的偏移量,即返回结构体初始内存地址到x之间的字节数。
总结:
- unsafe.Pointer 可以实现不同类型指针之间相互转化;
- uintptr 搭配着 unsafe.Pointer 使用,实现指针运算;
# 4.6 sync.pool
sync.Pool业务开发中不是一个常用结构,主要是为了解决Go GC压力过大问题的,所以一般情况下,当线上高并发业务出现GC问题需要被优化时,才需要用sync.Pool出场。
sync.pool的使用非常简单:
- 初始化Pool,提供一个New函数,当Pool中未缓存该对象时调用
- 使用Get从缓存池中获取对象,接着进行业务逻辑处理即可
- 使用完毕 利用Put将对象交还给缓存池
type Person struct {
Age int
}
var personPool = sync.Pool{
New: func() interface{} {
return new(Person)
},
}
func TestSyncPool(t *testing.T) {
// 获取一个实例
newPerson := personPool.Get().(*Person)
newPerson.Age = 25
// 回收对象 以备其他协程使用
personPool.Put(newPerson)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 4.6.1 缓存对象的数量和期限
上面我们可以看到pool创建的时候是不能指定大小的,所有sync.Pool的缓存对象数量是没有限制的(只受限于内存),因此使用sync.pool是没办法做到控制缓存对象数量的个数的。另外sync.pool缓存对象的期限是很诡异的,先看一下src/pkg/sync/pool.go里面的一段实现代码:
func init() {
runtime_registerPoolCleanup(poolCleanup)
}
2
3
可以看到pool包在init的时候注册了一个poolCleanup函数,它会清除所有的pool里面的所有缓存的对象,该函数注册进去之后会在每次gc之前都会调用,因此sync.Pool缓存的期限只是两次gc之间这段时间。正因gc的时候会清掉缓存对象,也不用担心pool会无限增大的问题。
正因为这样,我们是不可以使用sync.Pool去实现一个socket连接池的。
# 4.7 sync.cond
sync.Cond条件变量用来协调想要访问共享资源的那些 goroutine,当共享资源的状态发生变化的时候,它可以用来通知被互斥锁阻塞的 goroutine。
sync.Cond 基于互斥锁/读写锁,经常用在多个 goroutine 等待,一个 goroutine 通知(事件发生)的场景。
# 4.7.1 底层数据结构
type Cond struct {
noCopy noCopy
// L is held while observing or changing the condition
L Locker
notify notifyList
checker copyChecker
}
type notifyList struct {
wait uint32
notify uint32
lock uintptr // key field of the mutex
head unsafe.Pointer
tail unsafe.Pointer
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
主要有4个字段:
nocopy: golang 源码中检测禁止拷贝的技术。如果程序中有 WaitGroup 的赋值行为,使用 go vet 检查程序时,就会发现有报错,但需要注意的是,noCopy 不会影响程序正常的编译和运行checker:用于禁止运行期间发生拷贝,双重检查(Double check)L:可以传入一个读写锁或互斥锁,当修改条件或者调用Wait方法时需要加锁notify:通知链表,调用Wait()方法的Goroutine会放到这个链表中,从这里获取需被唤醒的Goroutine列表
# 4.7.2 使用方法
在Cond里主要有3个方法:
sync.NewCond(l Locker): 新建一个 sync.Cond 变量,注意该函数需要一个 Locker 作为必填参数,这是因为在 cond.Wait() 中底层会涉及到 Locker 的锁操作Cond.Wait(): 阻塞等待被唤醒,调用Wait函数前需要先加锁;并且由于Wait函数被唤醒时存在虚假唤醒等情况,导致唤醒后发现,条件依旧不成立,因此需要使用 for 语句来循环地进行等待,直到条件成立为止Cond.Signal(): 只唤醒一个最先 Wait 的 goroutine,可以不用加锁Cond.Broadcast(): 唤醒所有Wait的goroutine,可以不用加锁
package main
import (
"fmt""sync""sync/atomic""time"
)
var status int64func main() {
c := sync.NewCond(&sync.Mutex{})
for i := 0; i < 10; i++ {
go listen(c)
}
go broadcast(c)
time.Sleep(1 * time.Second)
}
func broadcast(c *sync.Cond) {
// 原子操作
atomic.StoreInt64(&status, 1)
c.Broadcast()
}
func listen(c *sync.Cond) {
c.L.Lock()
for atomic.LoadInt64(&status) != 1 {
c.Wait()
// Wait 内部会先调用 c.L.Unlock(),来先释放锁,如果调用方不先加锁的话,会报错
}
fmt.Println("listen")
c.L.Unlock()
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 4.8 互斥锁
Go sync包提供了两种锁类型:互斥锁sync.Mutex和读写互斥锁sync.RWMutex,都属于悲观锁。
# 4.8.1 底层实现结构
互斥锁对应的是底层结构是sync.Mutex结构体,,位于 src/sync/mutex.go中:
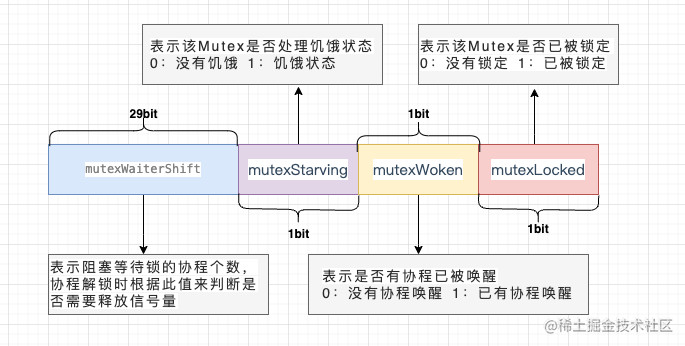
type Mutex struct {
state int32
sema uint32
}
2
3
4
state表示锁的状态,有锁定、被唤醒、饥饿模式等,并且是用state的二进制位来标识的,不同模式下会有不同的处理方式。
sema表示信号量,mutex阻塞队列的定位是通过这个变量来实现的,从而实现goroutine的阻塞和唤醒。

addr = &sema
func semroot(addr *uint32) *semaRoot {
return &semtable[(uintptr(unsafe.Pointer(addr))>>3)%semTabSize].root
}
root := semroot(addr)
root.queue(addr, s, lifo)
root.dequeue(addr)
var semtable [251]struct {
root semaRoot
...
}
type semaRoot struct {
lock mutex
treap *sudog // root of balanced tree of unique waiters.
nwait uint32 // Number of waiters. Read w/o the lock.
}
type sudog struct {
g *g
next *sudog
prev *sudog
elem unsafe.Pointer // 指向sema变量
waitlink *sudog // g.waiting list or semaRoot
waittail *sudog // semaRoot
...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 4.8.2 操作
锁的实现一般会依赖于原子操作、信号量,通过atomic包中的一些原子操作来实现锁的锁定,通过信号量来实现线程的阻塞与唤醒。
# 4.8.3 加锁
通过原子操作cas加锁,如果加锁不成功,根据不同的场景选择自旋重试加锁或者阻塞等待被唤醒后加锁
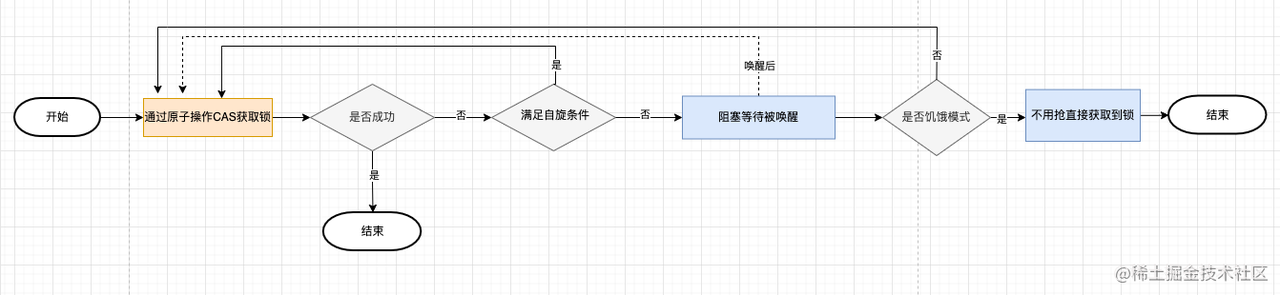
func (m *Mutex) Lock() {
// Fast path: 幸运之路,一下就获取到了锁if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
return
}
// Slow path:缓慢之路,尝试自旋或阻塞获取锁
m.lockSlow()
}
2
3
4
5
6
7
# 4.8.4 解锁
通过原子操作add解锁,如果仍有goroutine在等待,唤醒等待的goroutine。
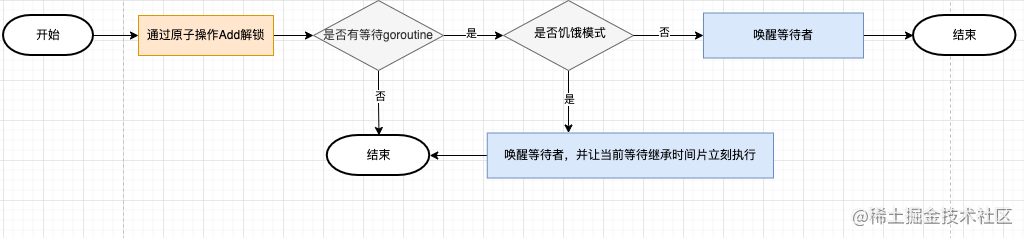
func (m *Mutex) Unlock() {
// Fast path: 幸运之路,解锁new := atomic.AddInt32(&m.state, -mutexLocked)
if new != 0 {
// Slow path:如果有等待的goroutine,唤醒等待的goroutine
m.unlockSlow()
}
}
2
3
4
5
6
7
注意点:
- 在
Lock()之前使用 Unlock() 会导致panic异常 - 使用
Lock()加锁后,再次Lock()会导致死锁(不支持重入),需Unlock()解锁后才能再加锁 - 锁定状态与 goroutine 没有关联,一个 goroutine 可以 Lock,另一个 goroutine 可以 Unlock
# 4.8.5 Go 互斥锁正常模式和饥饿模式
在Go一共可以分为两种抢锁的模式,一种是正常模式,另外一种是饥饿模式。
# 4.8.5.1 正常模式(非公平锁)
在刚开始的时候,是处于正常模式(Barging),也就是,当一个G1持有着一个锁的时候,G2会自旋的去尝试获取这个锁。
当自旋超过4次还没有能获取到锁的时候,这个G2就会被加入到获取锁的等待队列里面,并阻塞等待唤醒。
正常模式下,所有等待锁的 goroutine 按照 FIFO(先进先出)顺序等待。唤醒的goroutine 不会直接拥有锁,而是会和新请求锁的 goroutine 竞争锁。新请求锁的 goroutine 具有优势:它正在 CPU 上执行,而且可能有好几个,所以刚刚唤醒的 goroutine 有很大可能在锁竞争中失败,长时间获取不到锁,就会切换到饥饿模式。
# 4.8.5.2 饥饿模式(公平锁)
当一个 goroutine 等待锁时间超过 1 毫秒时,它可能会遇到饥饿问题。 在版本1.9中,这种场景下Go Mutex 切换到饥饿模式(handoff),解决饥饿问题。
starving = runtime_nanotime()-waitStartTime > 1e6
正常模式下,所有等待锁的 goroutine 按照 FIFO(先进先出)顺序等待。唤醒的goroutine 不会直接拥有锁,而是会和新请求锁的 goroutine 竞争锁。
新请求锁的 goroutine 具有优势:它正在 CPU 上执行,而且可能有好几个,所以刚刚唤醒的 goroutine 有很大可能在锁竞争中失败,长时间获取不到锁,就会切换到饥饿模式。
那么也不可能说永远的保持一个饥饿的状态,总归会有吃饱的时候,也就是总有那么一刻Mutex会回归到正常模式,那么回归正常模式必须具备的条件有以下几种:
- G的执行时间小于1ms
- 等待队列已经全部清空了
当满足上述两个条件的任意一个的时候,Mutex会切换回正常模式,而Go的抢锁的过程,就是在这个正常模式和饥饿模式中来回切换进行的。
delta := int32(mutexLocked - 1<<mutexWaiterShift)
if !starving || old>>mutexWaiterShift == 1 {
delta -= mutexStarving
}
atomic.AddInt32(&m.state, delta)
2
3
4
5
总结:
对于两种模式,正常模式下的性能是最好的,goroutine 可以连续多次获取锁,饥饿模式解决了取锁公平的问题,但是性能会下降,其实是性能和公平的一个平衡模式。
# 4.9 Go 原子操作和锁的区别?
- 原子操作由底层硬件支持,而锁是基于原子操作+信号量完成的。若实现相同的功能,前者通常会更有效率
- 原子操作是单个指令的互斥操作;互斥锁/读写锁是一种数据结构,可以完成临界区(多个指令)的互斥操作,扩大原子操作的范围
- 原子操作是无锁操作,属于乐观锁;说起锁的时候,一般属于悲观锁
- 原子操作存在于各个指令/语言层级,比如“机器指令层级的原子操作”,“汇编指令层级的原子操作”,“Go语言层级的原子操作”等。
- 锁也存在于各个指令/语言层级中,比如“机器指令层级的锁”,“汇编指令层级的锁”,“Go语言层级的锁”等
# 4.10 死锁和解决方案
常见死锁情况:
- channel阻塞
- 锁嵌套/重复加锁
解决方案:
- 控制锁的力度,保持最够小
- 谨记channel的使用特性
# 5. 其他
# 5.1 defer常见问题
# 5.1.1 特性
defer语句延迟执行了一个匿名函数,因为这个匿名函数捕获了外部函数的局部变量 v,这种函数我们一般叫闭包。闭包对捕获的外部变量并不是传值方式访问,而是以引用的方式访问。- 函数的
return语句并不是原子级的,实际上return语句只代理汇编指令ret。返回过程是:「设置返回值—>执行defer—>ret」
# 5.1.2 defer的执行顺序
- 多个defer出现的时候,它是一个“栈”的关系,也就是先进后出。一个函数中,写在前面的defer会比写在后面的defer调用的晚(定义顺序与实际执行顺序相反)。
- defer会影响return返回,有名函数返回的时候,如果defer中操作了有名函数的返回列表中的变量,将会影响return返回(这是变量作用域的问题)
# 5.1.3 defer可以捕获goroutine的子goroutine吗?
不可以, 它们处于不同的调度器P中。对于子goroutine,必须通过recover()机制来进行恢复。
# 5.2 Go程序性能分析优化
time命令
$ time date
Mon Sep 26 23:40:35 CST 2022
real 0m0.001s
user 0m0.000s
sys 0m0.001s
2
3
4
5
6
上面是使用time对go run test.go对执行程序进行性能分析,得到3个指标:
real:从程序开始到结束,实际度过的时间 user:程序在用户态度过的时间 sys:程序在内核态度过的时间
/usr/bin/time命令/usr/bin/time这个指令比内置的time更加详细一些,使用的时候需要用绝对路径,而且要加上参数-v
$ /usr/bin/time -v date
Mon Sep 26 23:40:22 CST 2022
Command being timed: "date"
User time (seconds): 0.00
System time (seconds): 0.00
Percent of CPU this job got: ?%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:00.00
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 2208
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 0
Minor (reclaiming a frame) page faults: 121
Voluntary context switches: 1
Involuntary context switches: 1
Swaps: 0
File system inputs: 0
File system outputs: 0
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
top命令GODEBUG 在执行程序之前添加环境变量GODEBUG='gctrace=1'来跟踪打印垃圾回收器信息
GODEBUG='gctrace=1' ./main
设置gctrace=1会使得垃圾回收器在每次回收时汇总所回收内存的大小以及耗时, 并将这些内容汇总成单行内容打印到标准错误输出中。
gc # GC次数的编号,每次GC时递增
@#s 距离程序开始执行时的时间
#% GC占用的执行时间百分比
#+...+# GC使用的时间
#->#-># MB GC开始,结束,以及当前活跃堆内存的大小,单位M
# MB goal 全局堆内存大小
# P 使用processor的数量
2
3
4
5
6
7
- runtime.ReadMemStats
package main
import (
"log"
"runtime"
"time"
)
func readMemStats() {
var ms runtime.MemStats
runtime.ReadMemStats(&ms)
log.Printf(" ===> Alloc:%d(bytes) HeapIdle:%d(bytes) HeapReleased:%d(bytes)", ms.Alloc, ms.HeapIdle, ms.HeapReleased)
}
func test() {
//slice 会动态扩容,用slice来做堆内存申请
container := make([]int, 8)
log.Println(" ===> loop begin.")
for i := 0; i < 32*1000*1000; i++ {
container = append(container, i)
if ( i == 16*1000*1000) {
readMemStats()
}
}
log.Println(" ===> loop end.")
}
func main() {
log.Println(" ===> [Start].")
readMemStats()
test()
readMemStats()
log.Println(" ===> [force gc].")
runtime.GC() //强制调用gc回收
log.Println(" ===> [Done].")
readMemStats()
go func() {
for {
readMemStats()
time.Sleep(10 * time.Second)
}
}()
time.Sleep(3600 * time.Second) //睡眠,保持程序不退出
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
- pprof工具
# 5.3 Go如何避免panic
# 5.3.1 常见panic情况
- 空指针: 对空指针进行操作;
- 数组/切片:数组/切片越界操作;
- Channel: 如果我们关闭未初始化的通道,重复关闭通道,向已经关闭的通道中发送数据;
- Map: map未进行初始化进行操作;map并发读写;
- 类型断言:未对类型断言结果进行判断;
# 5.3.2 避免panic方案
- 对竞争资源进行加锁,避免出现竞态;
- map/channel需要初始化后再使用;
- 通过
recover()进行捕获(有些panic无法recover(),比如map并发读写)
# 5.4 常见坑
- forRange: 使用
for i,v := range遍历值类型时,其中的v变量是一个值的拷贝,当使用&获取指针时,实际上是获取到v这个临时变量的地址,而v变量在for range中只会创建一次,之后循环中会被一直重复使用,若使用该变量的地址,会造成不可预知的问题。
# 5.5 init函数
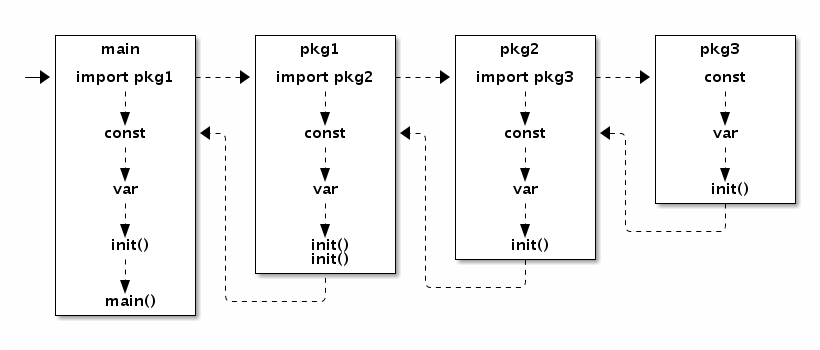
- init()函数是go初始化的一部分,由runtime初始化每个导入的包,初始化不是按照从上到下的导入顺序,而是按照解析的依赖关系,没有依赖的包最先初始化。
- 每个包首先初始化包作用域的常量和变量(常量优先于变量),然后执行包的init()函数。同一个包,甚至是同一个源文件可以有多个init()函数。init()函数没有入参和返回值,不能被其他函数调用,同一个包内多个init()函数的执行顺序不作保证。
- 如果一个包有多个 init 函数的话,调用顺序未定义(实现可能是以文件名的顺序调用),同一个文件内的多个 init 则是以出现的顺序依次调用。
执行顺序:
import –> const –> var –>init()–>main()
# 5.6 位运算
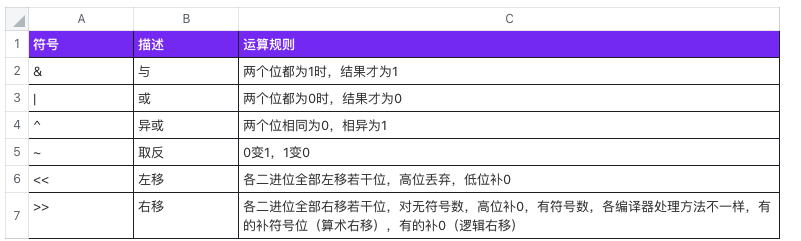
# 5.6.1 位运算的使用场景
# 5.6.1.1 与运算符
- 清零:如果想将一个单元清零,即使其全部二进制位为0,只要与一个各位都为零的数值相与,结果为零。
- 判断奇偶:只要根据最未位是0还是1来决定,为0就是偶数,为1就是奇数。因此可以用if ((a & 1) == 0)代替if (a % 2 == 0)来判断a是不是偶数。
# 5.6.1.2 左移/右移
A. 简单记法
- 3<<4 :表示为3乘以2的4次方
- 2>>3 :表示为2除以2的3次方 左移乘以2的N次方,右移除以2的N次方
B. 使用场景 假设有两个数,A和B(A>0,B>0)。B为2^n,期中n>=0,A>=0。则:(原来B得为2^n)
- 要求A * B的话,则可使用<<操作符,A << n。
- 要求A / B的话,则可使用>>操作符,A >> n。
- 要求A % B的话,则可使用&操作符,A&(B-1)。
# 5.7 Go编程哲学
# 5.7.1 少即是多
只提供一种方法,把事情做到极致;比如循环只提供for关键字,没有必要引入 while , do while。
# 5.7.2 组合优于继承
继承关系是世界万物的关系中一个非常小的子集,组合才是世界万物基本的、常见的关系。所以以继承为基础的面向对象语言存在表现力不足,最后不得不高出一套设计模式来弥补这个缺陷。Go语言选择的是组合的思想,这是和现实世界万物关系比较吻合的设计,表现力更强。Go编程中不会有所谓的23种设计模式,Go使用一种很自然的方式来建模世界,解决问题。
# 5.7.3 非侵入式的接口
Go语言接口采用的是一种Duck模型,具体类型不需要显式地声明自己实现了某个接口,只要其方法集是接口方法集的超集即可。使接口和实现者彻底解耦。显式的借口声明显然要求人具备上帝视角,整个接口继承体系一开始就要进行精心和周全的设计。Go不一样,Go倾向于小粒度的接口设计,通过接口组合,自由组合成新的接口,这和人类对世界基本认知的过程一致,便于后续代码的重构和优化。
# 5.7.4 Goroutine设计
- 虽然线程的代价比进程小了很多,但我们依然不能大量创建线程,因为不仅每个线程占用的资源不小,操作系统调度切换线程的代价也不小。对于很多网络服务程序,由于不能大量创建线程,就要在少量线程里做网络的多路复用,即使用epoll/kqueue/IoCompletionPort这套机制。即便有了libevent、libev这样的第三方库的帮忙,写起这样的程序也是很不容易的,存在大量回调(callback),会给程序员带来不小的心智负担。
- Go果断放弃了传统的基于操作系统线程的并发模型,而采用了用户层轻量级线程或者说是类协程(coroutine),Go将之称为goroutine。goroutine占用的资源非常少,Go运行时默认为每个goroutine分配的栈空间仅2KB。goroutine调度的切换也不用陷入(trap)操作系统内核层完成,代价很低。
- 一个Go程序对于操作系统来说只是一个用户层程序。操作系统的眼中只有线程,它甚至不知道goroutine的存在。goroutine的调度全靠Go自己完成,实现Go程序内goroutine之间公平地竞争CPU资源的任务就落到了Go运行时头上。而将这些goroutine按照一定算法放到CPU上执行的程序就称为goroutine调度器(goroutine scheduler)
- 去除包的循环依赖。循环依赖会在大规模的代码中引发问题,因为它们要求编译器同时处理更大的源文件集,这会减慢增量构建速度。在处理依赖关系时,有时会通过允许一部分重复代码来避免引入较多依赖关系。比如:net包具有其自己的整数到十进制转换实现,以避免依赖于较大且依赖性较强的格式化io包。
# 6. 新特性
# 6.1 泛型
泛型是Go1.18版本发布的新特性,接触过Java编程的都知道泛型的用法。
泛型示例:
type Stack[T any] struct {
vals []T
}
func (s *Stack[T]) Push(val T) {
s.vals = append(s.vals, val)
}
func (s *Stack[T]) Pop() (T, bool) {
if len(s.vals) == 0 {
var zero T
return zero, false
}
top := s.vals[len(s.vals)-1]
s.vals = s.vals[:len(s.vals)-1]
return top, true
}
func TestFanXing(t *testing.T) {
var intStack Stack[int]
intStack.Push(10)
intStack.Push(20)
intStack.Push(30)
v, ok := intStack.Pop()
fmt.Println(v, ok)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26