阿里开源ETL工具:dataX上手指南
阿里开源ETL工具:dataX上手指南
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS 等各种异构数据源之间高效的数据同步功能。
开源地址:https://github.com/alibaba/DataX
# 设计思想
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
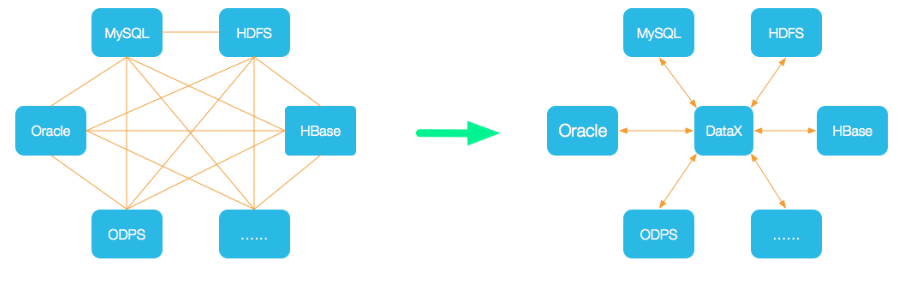
数据交换通过DataX进行中转,任何数据源只要和DataX连接上即可以和已实现的任意数据源同步

核心组件:
- **Reader:**数据采集模块,负责从源采集数据
- **Writer:**数据写入模块,负责写入目标库
- **Framework:**数据传输通道,负责处理数据缓冲等
以上只需要重写Reader与Writer插件,即可实现新数据源支持d支持主流数据源,详见:https://github.com/alibaba/DataX/blob/master/introduction.md
# 核心架构
DataX 3.0 开源版本支持单机多线程模式完成同步作业运行,本小节按一个DataX作业生命周期的时序图,从整体架构设计非常简要说明DataX各个模块相互关系。
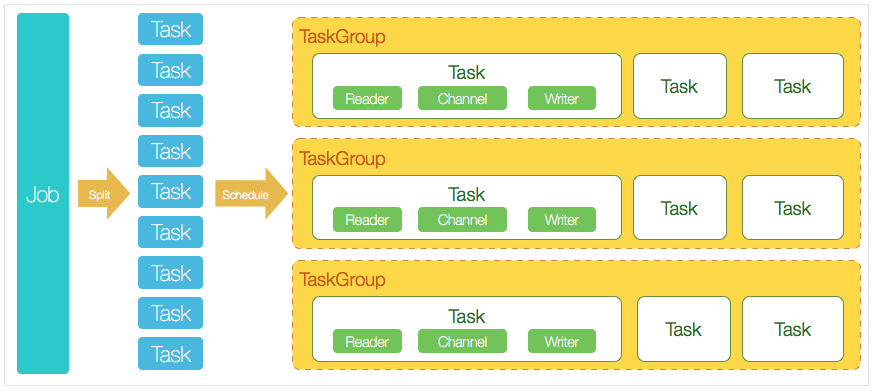
从一个JOB来理解datax的核心模块组件:
- datax完成单个数据同步的作业,称为Job,job会负责数据清理、任务切分等工作;
- 任务启动后,Job会根据不同源的切分策略,切分成多个Task并发执行,Task就是执行作业的最小单元;
- 切分完成后,根据Scheduler模块,将Task组合成TaskGroup,每个group负责一定的并发和分配Task;
# 入门
# 环境要求
- Linux
- JDK(1.6以上,推荐1.6.x) (opens new window)
- Python(推荐Python2.6.X) (opens new window)
- Apache Maven 3.x (opens new window) (若不编译DataX源码,则不需要)
# 工具部署
方法一:安装包安装
直接下载DataX工具包:DataX (opens new window),下载后解压至本地某个目录,进入bin目录,即可运行同步作业
$ cd {YOUR_DATAX_HOME}/bin
$ python datax.py {YOUR_JOB.json}
2
同步作业配置模板,请参考DataX各个插件配置模板和参数说明 (opens new window)
方法二:编译安装
下载DataX源码,自己编译:DataX源码 (opens new window)
- 下载DataX源码:
$ git clone git@github.com:alibaba/DataX.git
- 通过maven打包:
$ cd {DataX_source_code_home}
$ mvn -U clean package assembly:assembly -Dmaven.test.skip=true
2
打包成功,日志显示如下:
[INFO] BUILD SUCCESS
[INFO] ————————————————————————————————-
[INFO] Total time: 08:12 min
[INFO] Finished at: 2015-12-13T16:26:48+08:00
[INFO] Final Memory: 133M/960M
[INFO] ————————————————————————————————-
2
3
4
5
6
打包成功后的DataX包位于 {DataX_source_code_home}/target/datax/datax/ ,结构如下:
$ cd {DataX_source_code_home}
$ ls ./target/datax/datax/
bin conf job lib log log_perf plugin script tmp
2
3
# 配置示例
示例:从stream读取数据并打印到控制台
第一步、创建创业的配置文件(json格式)
#stream2stream.json
{
"job": {
"setting": {
"speed": {
"channel": 5
}
},
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"sliceRecordCount": 10,
"column": [
{
"type": "long",
"value": "10"
},
{
"type": "string",
"value": "hello,你好,世界-DataX"
},
{
"type": "double",
"value": "3.141592653"
},
{
"type": "bytes",
"value": "image"
},
{
"type": "bool",
"value": "true"
},
{
"type": "bool",
"value": "5678true"
},
{
"type": "date",
"value": "2014-10-10",
"dateFormat": "yyyy-MM-dd"
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": true
}
}
}
]
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
第二步:启动DataX
$ cd {YOUR_DATAX_DIR_BIN}
$ python datax.py ./stream2stream.json
2
同步结束,显示日志如下:
2015-12-17 11:20:25.263 [job-0] INFO JobContainer -
任务启动时刻 : 2015-12-17 11:20:15
任务结束时刻 : 2015-12-17 11:20:25
任务总计耗时 : 10s
任务平均流量 : 205B/s
记录写入速度 : 5rec/s
读出记录总数 : 50
读写失败总数 : 0
2
3
4
5
6
7
8
其他reader与writer插件的配置文档直接点击对应的文件夹进入doc即可。