 大数据基础知识总结
大数据基础知识总结
# 结构化数据和非结构化数据
# 结构化数据
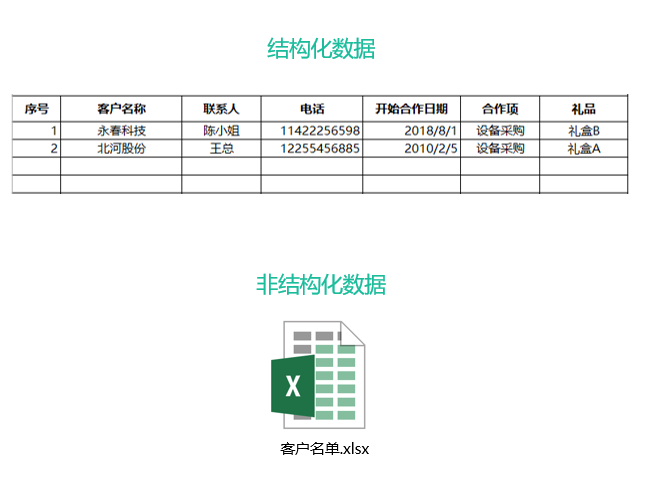
结构化数据是指可以使用关系型数据库表示和存储,表现为二维形式的数据。简单来说就是数据库。一般特点是:数据以行为单位,一行数据表示一个实体的信息,每一行数据的属性是相同的。所以,结构化数据的存储和排列是很有规律的。
# 非架构化数据
非结构化数据是数据结构不规则或不完整,没有预定义的数据模型,不方便用数据库二维逻辑表来表现的数据。包括所有格式的办公文档、文本、图片、各类报表、图像和音频/视频等。非结构化数据其格式非常多样,标准也是多样性的。两者的概念并不难区分,如果用一份Excel报表来理解,这份文件本身是非结构化数据,而里面内容则是结构化数据。
# OLTP和OLAP
OLTP(在线事务处理)优化的方向是高并发、高可用,是精确,是各种增删改查。所以面临和解决的问题都是怎么解决高并发下的增删改查,怎么解决脏读、脏写,保证数据一致性等问题。 OLAP(在线分析处理)的优化方向则是高速数据处理能力、高速读取能力。一般又分为两个优化方向,一个是预先计算好各个维度的数据,存成CUBE,分析的时候直接查询结果就行,这是MOLAP(Multidimensional OLAP,多维在线分析处理),典型代表的是Kylin。一个是结构化存好,然后用尽各种方法优化,分析的时候拼命计算,这是ROLAP(Relational OLAP,关系型在线分析处理),典型代表就是ClickHouse了。
# 数据库架构设计
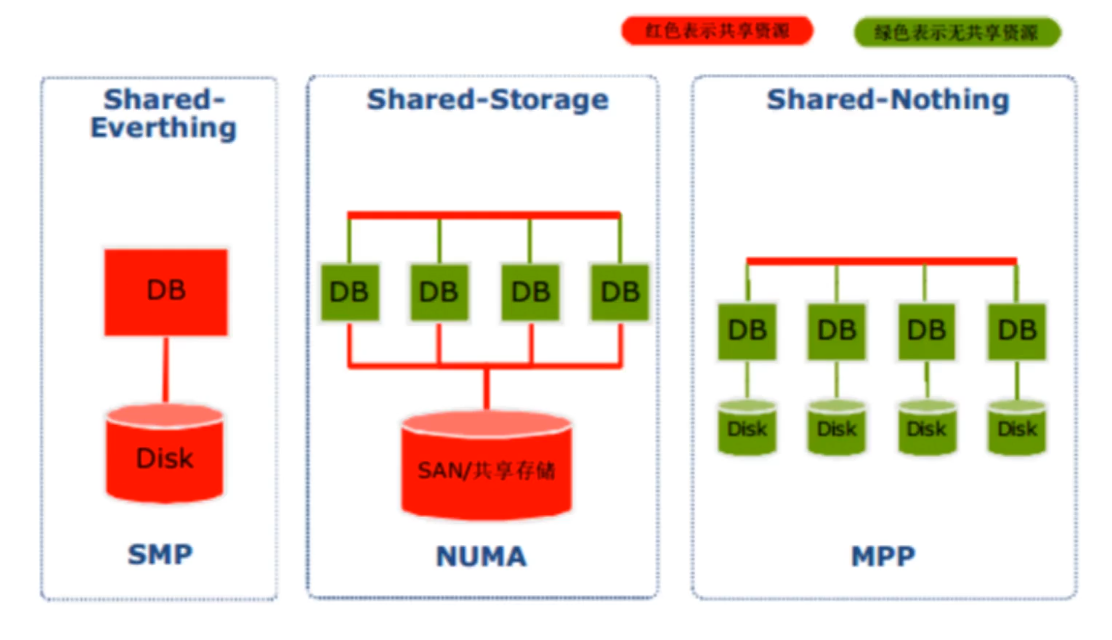
- Shared Everthing:完全透明共享 CPU/MEMORY/IO,并行处理能力是最差的;如:SQL Server
- Shared Storage:各个处理单元使用自己的私有 CPU 和 Memory,共享磁盘系统;
- Shared Nothing:各个处理单元都有自己私有的 CPU/内存/磁盘;
# MPP架构
MPP (Massively Parallel Processing),即大规模并行处理。简单来说,MPP是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果(与Hadoop相似)。
MPP架构特征
- 任务并行执行;
- 数据分布式存储(本地化);
- 分布式计算;
- 私有资源;
- 横向扩展;
- Shared Nothing架构。
# 什么是MPP数据库?
MPP数据库是一款 Shared Nothing架构的分布式并行结构化数据库集群,具备高性能、高可用、高扩展特性,可以为超大规模数据管理提供高性价比的通用计算平台,并广泛地用于支撑各类数据仓库系统、BI 系统和决策支持系统
# 常用数据库
# Apache Kylin
# Clickhouse
ClickHouse 是 MPP 架构的列式存储 RDBMS (关系型数据库),通过极致使用 CPU 的性能达到高性能的 OLAP 分析。
ClickHouse在运行的时候,会用掉服务器的所有资源,不仅仅是内存哦!甚至你查一个简单但是数据,都会吃掉50%以上的CPU!!!
另外,CK还有以下特性:
- PB级数据处理能力
- 列式数据存储
- 优秀的数据压缩
- 多核并行处理
- 多服务器分布式处理
- SQL支持(部分语句有点怪)
- 向量化引擎
- 支持实时数据更新
- 高吞吐写入
- 近似计算
- 少依赖,上手非常容易
至于不支持事务处理、不太支持删除、修改等问题,这根本就是不OLAP的需要好么?虽然说数仓也偶然会有改数据的可能,但要支持的那么好干啥?对吧?
ClickHouse 适合低并发,灵活即席查询场景,也支持例如:报表分析,留存分析,用户标签画像分析,用户行为漏斗分析,归因分析等.