Mysql主从复制
Mysql主从复制
Mysql作为目前世界上使用最广泛的关系型数据库,在实际的生产环境中,其安全性,高可用性以及高并发等各个方面,单台Mysql数据库是无法满足需求的。读写集中在单台Mysql服务器上让数据库不堪重负,大部分系统使用主从复制技术来达到读写分离,以提高读写性能和读库的可扩展性。
# 实现原理
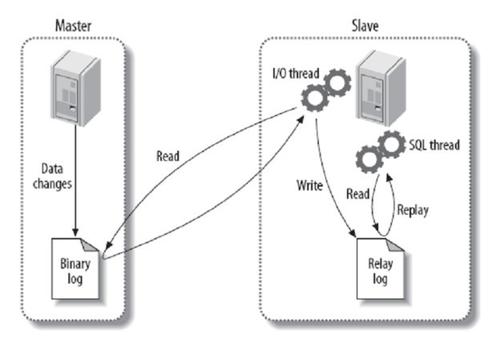
- 主服务器上面的任何修改都会保存在二进制日志Binary log里面;
- 从服务器上面启动一个I/O thread(实际上就是一个主服务器的客户端进程),连接到主服务器上面请求读取二进制日志,然后把读取到的二进制日志写到本地的一个Relay log里面;
- 从服务器上面开启一个SQL thread定时检查Relay log,如果发现有更改立即把更改的内容在本机上面执行一遍。
# 实现过程
- Slave上面的IO进程连接上Master,并请求从指定日志文件的指定位置(或者从最开始的日志)之后的日志内容。
- Master接收到来自Slave的IO进程的请求后,负责复制的IO进程会根据请求信息读取日志指定位置之后的日志信息,返回给Slave的IO进程。返回信息中除了日志所包含的信息之外,还包括本次返回的信息已经到Master端的bin-log文件的名称以及bin-log的位置。
- Slave的IO进程接收到信息后,将接收到的日志内容依次添加到Slave端的relay-log文件的最末端,并将读取到的Master端的 bin-log的文件名和位置记录到master-info文件中,以便在下一次读取的时候能够清楚的告诉Master从何处开始读取日志。
- Slave的Sql进程检测到relay-log中新增加了内容后,会马上解析relay-log的内容成为在Master端真实执行时候的那些可执行的内容,并在自身执行。
# 部署实施
# 主(master)服务器
# 修改主(master)服务器
在my.cnf配置文件下添加如下配置(配置完需要重启Mysql服务器):
[mysqld]
## 同一局域网内注意要唯一
server-id=1
## 指定mysql的binlog的存放路径,默认会存放到mysql的data目录下
log-bin=mysql-bin
2
3
4
5
# 创建复制账号
在master数据库创建数据同步用户,授予用户 slave REPLICATION SLAVE权限和REPLICATION CLIENT权限,用于在主从库之间同步数据。
CREATE USER 'tongbu'@'%' IDENTIFIED BY '123456';
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'tongbu'@'%';
2
# 查看主服务器状态
show master status;

这里的信息需要记录下来,在配置从服务器时候需要用到
# 从(slave)服务器
# 修改从(slave)服务器
在my.cnf配置文件下添加如下配置(配置完需要重启Mysql服务器):
[mysqld]
## 设置server_id,注意要唯一
server-id=2
## 开启二进制日志功能,以备Slave作为其它Slave的Master时使用
log-bin=mysql-slave-bin
## 指定relay_log日志的存放路径和文件前缀,不指定的话默认以主机名作为前缀
relay_log=slave-relay-bin
2
3
4
5
6
7
# 配置从服务器
配置从服务器,连接到Master服务器。
change master to master_host='192.168.0.2', master_user='tongbu', master_password='123456', master_port=3306, master_log_file='mysql-bin.000011', master_log_pos= 154, master_connect_retry=30;
- master_host:主服务器的IP
- master_port:3306(这里没有配置,默认3306)
- master_user:Master 服务器授权用户,也就是 Master 前面创建的那个用户
- master_password:Master 服务器授权用户对应的密码
- master_log_file:Master binlog 文件名
- master_log_pos:Master binlog 文件中的 Postion 值
关于position值,这里做一个说明:如果主服务器已经是有很多数据了的,那就先需要备份主服务器的数据到从服务器中,然后再使用命令show master status记录需要开始同步的位置。
# 开启主从复制
在从服务器中执行:
## 启动复制
start slave;
## 关闭复制
stop slave;
2
3
4
# 查看从服务器状态
show slave status\G;
# 主从同步的粒度
主从同步主要有三种形式:statement、row、mixed。
# statemnet
每一条会修改数据的sql都会记录在binlog中。
优点:不需要记录每一行的变化,减少了binlog日志量,节约了IO,提高性能。只需要记录在 master 上所执行的语句的细节,以及执行语句时候的上下文的信息。
缺点:由于记录的只是执行语句,为了这些语句能在slave上正确运行,因此还必须记录每条语句在执行的时候的一些相关信息,以保证所有语句能在slave得到和在master端执行时候相同的结果。像一些特定函数功能,slave可与master上要保持一致会有很多相关问题(如sleep()函数,rand()函数等会出现问题warning)
# row
不记录sql语句上下文相关信息,仅保存哪条记录被修改,也就是说日志中会记录成每一行数据被修改的形式,然后在 slave 端再对相同的数据进行修改。
优点:binlog中可以不记录执行的sql语句的上下文相关的信息,仅需要记录那一条记录被修改成什么了。所以rowlevel的日志内容会非常清楚的记录下每一行数据修改的细节。而且不会出现某些特定情况下的存储过程,或function,以及trigger的调用和触发无法被正确复制的问题。
缺点:在 row 模式下,所有的执行的语句当记录到日志中的时候,都将以每行记录的修改来记录,这样可能会产生大量的日志内容。
# MIXED
是以上两种level的混合使用,一般的语句修改使用statment格式保存binlog,如一些函数,statement无法完成主从复制的操作,则采用row格式保存binlog,MySQL会根据执行的每一条具体的sql语句来区分对待记录的日志形式,也就是在Statement和Row之间选择一种;
新版本的MySQL中对row模式也被做了优化,并不是所有的修改都会以rowl来记录,像遇到表结构变更的时候就会以statement模式来记录。至于update或者delete等修改数据的语句,还是会记录所有行的变更。
# 主从复制类型
# 基于二进制日志的复制
即基于Binary log实现的复制机制,从库需要告知主库要从哪个偏移量进行增量同步,如果指定错误会造成数据的遗漏,从而造成数据的不一致。
# GTID基于事务的复制
GTID (Global Transaction ID) )即全局事务ID,是对于一个已提交事务的全局唯一编号,由UUID+TID组成的,其中 UUID 是一个 MySQL 实例的唯一标识,保存在mysql数据目录下的auto.cnf文件里。TID 代表了该实例上已经提交的事务数量,并且随着事务提交单调递增。下面是一个GTID的具体形式:
3E11FA47-71CA-11E1-9E33-C80AA9429562:23
# GTID工作原理
- Master更新数据时,会在事务前产生GTID,一同记录到binlog日志中;
- Slave在接受Master的binlog时,会校验Master的GTID是否已经执行过
- Slave端的I/O线程将变更的binlog,写入到本地的relay log中;
- Sql线程从relay log中获取GTID,然后对比Slave端的binlog是否有记录;
- 如果有记录,说明该GTID的事务已经执行,slave会忽略;
- 如果没有记录,slave就会从relay log中执行该GTID的事务,并记录到binlog
借助GTID,在发生主备切换的情况下,MySQL的其它从库可以自动在新主库上找到正确的复制位置,这大大简化了复杂复制拓扑下集群的维护,也减少了人为设置复制位置发生误操作的风险。另外,基于GTID的复制可以忽略已经执行过的事务,减少了数据发生不一致的风险。
# GTID配置
在my.cnf配置文件下添加如下配置(配置完需要重启Mysql服务器):
[mysqld]
#GTID:
gtid_mode=on
enforce_gtid_consistency=on
2
3
4
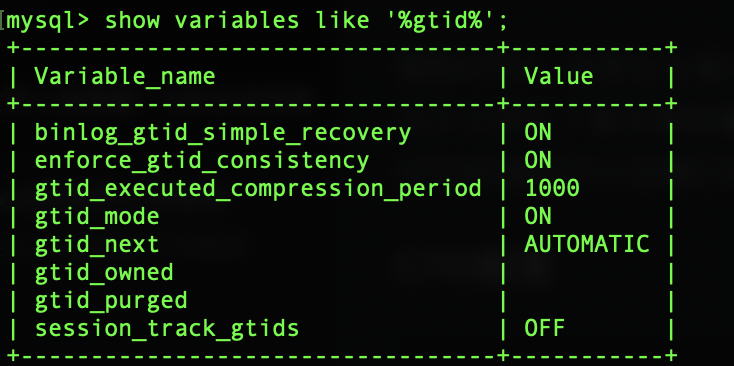
重启Mysql,查看GTID开启状态:
show variables like '%gtid%';