 RabbitMQ集群实践
RabbitMQ集群实践
RabbitMQ有三种运行模式:
- 单机模式
- 集群模式
- 镜像模式
# 单机模式
单机模式比较简单,采用单机单应用配置,安装rabbitmq即可。
# 集群模式
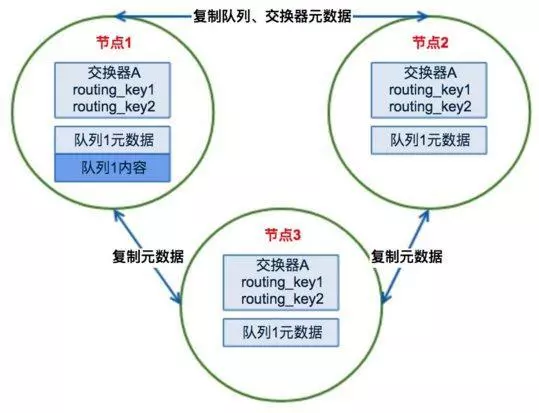
RabbitMQ集群中节点包括内存节点、磁盘节点。内存节点就是将所有数据放在内存,磁盘节点将数据放在磁盘上。如果在投递消息时,打开了消息的持久化,那么即使是内存节点,数据还是安全的放在磁盘。一个集群至少要有一个磁盘节点。一个rabbitmq集群中可以共享user,vhost,exchange等,所有的数据和状态都是必须在所有节点上复制的,对于queue根据集群模式不同,应该有不同的表现。在集群模式下只要有任何一个节点能够工作,RabbitMQ集群对外就能提供服务。
默认的集群模式,queue创建之后,如果没有其它policy,则queue就会按照普通模式集群。对于Queue来说,消息实体只存在于其中一个节点,A、B两个节点仅有相同的元数据,即队列结构,但队列的元数据仅保存有一份,即创建该队列的rabbitmq节点(A节点),当A节点宕机,你可以去其B节点查看rabbitmqctl list_queues发现该队列已经丢失,但声明的exchange还存在。
当消息进入A节点的Queue中后,consumer从B节点拉取时,RabbitMQ会临时在A、B间进行消息传输,把A中的消息实体取出并经过B发送给consumer,所以consumer应平均连接每一个节点,从中取消息。该模式存在一个问题就是当A节点故障后,B节点无法取到A节点中还未消费的消息实体。如果做了队列持久化或消息持久化,那么得等A节点恢复,然后才可被消费,并且在A节点恢复之前其它节点不能再创建A节点已经创建过的持久队列;如果没有持久化的话,消息就会失丢。这种模式更适合非持久化队列,只有该队列是非持久的,客户端才能重新连接到集群里的其他节点,并重新创建队列。假如该队列是持久化的,那么唯一办法是将故障节点恢复起来。
由于服务器资源有限,我们采用Docker在单机上部署测试集群。
# 下载RabbitMQ镜像
docker pull rabbitmq:3.7.17-management
注意使用后缀为"-management"的镜像版本,是包含网页控制台的。
使用命令docker images查看已下载的镜像,如下所示:
gitlub@devops:~$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
rabbitmq 3.7.17-management 7601e834fa14 3 weeks ago 177MB
2
3
# 创建Docker网络
docker network create --subnet=172.100.100.0/16 rabbitmq-net
创建专用docker网络后,可以通过docker network ls命令查看当前docker已经创建的网络,如下所示:
gitlib@devops:/www/websites/www/gitlib/practise/php/rabbitmq$ docker network ls
NETWORK ID NAME DRIVER SCOPE
b080d0014865 bridge bridge local
0a6bb5c1600b host host local
5b6753d359b4 kong-net bridge local
7ed27bb87f51 none null local
7b6e8c374455 rabbitmq-net bridge local
2
3
4
5
6
7
8
# 搭建RabbitMQ集群
我们采用3个节点来搭建RabbitMQ集群:
| 节点 | IP |
|---|---|
| rabbit1 | 172.100.100.2 |
| rabbit2 | 172.100.100.3 |
| rabbit3 | 172.100.100.4 |
# 安装RabbitMQ
安装节点1:
docker run -d --hostname rabbit1 --name myrabbit1 -p 15672:15672 -p 5672:5672 -e RABBITMQ_ERLANG_COOKIE='rabbitcookie' --net=rabbitmq-net --ip=172.100.100.2 rabbitmq:3.7.17-management
安装节点2:
docker run -d --hostname rabbit2 --name myrabbit2 -p 5673:5672 --link myrabbit1:rabbit1 -e RABBITMQ_ERLANG_COOKIE='rabbitcookie' --net=rabbitmq-net --ip=172.100.100.3 rabbitmq:3.7.17-management
安装节点3:
run -d --hostname rabbit3 --name myrabbit3 -p 5674:5672 --link myrabbit1:rabbit1 --link myrabbit2:rabbit2 -e RABBITMQ_ERLANG_COOKIE='rabbitcookie' --net=rabbitmq-net --ip=172.100.100.4 rabbitmq:3.7.17-management
注意点:
- 多个容器之间使用“--link”连接,此属性不能少;
- Erlang Cookie值必须相同,也就是RABBITMQ_ERLANG_COOKIE参数的值必须相同,原因见下文“配置相同Erlang Cookie”部分;
# 加入RabbitMQ节点到集群
设置节点2和节点3,加入到节点1的集群中:
设置节点2,加入到集群:
docker exec -it myrabbit2 bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster --ram rabbit@rabbit1
rabbitmqctl start_app
exit
2
3
4
5
6
设置节点3,加入到集群:
docker exec -it myrabbit3 bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster --ram rabbit@rabbit1
rabbitmqctl start_app
exit
2
3
4
5
6
设置好之后,使用http://物理机ip:15672 进行访问了,默认账号密码是guest/guest,效果如下图:

# 缺点
普通集群模式,并不保证队列的高可用性。尽管交换机、绑定这些可以复制到集群里的任何一个节点,但是队列内容不会复制。虽然该模式解决一项目组节点压力,但队列节点宕机直接导致该队列无法应用,只能等待重启。所以要想在队列节点宕机或故障也能正常应用,就要复制队列内容到集群里的每个节点,也就是必须要创建镜像队列。
# 镜像模式
在同一个RabbitMQ集群中,节点之间并没有主从之分,所有节点会同步相同的队列结构,队列内容(消息)则各自不同,不过消息会在节点间传递。这样的集群只是提高了应对大量并发请求的能力,整体可用性还是很低,因为某个节点宕机后,寄存在该节点上的消息不可用,而在其他节点上也没有这些消息的备份,若是该节点无法恢复,那么这些消息就丢失了。
将需要消费的队列变为镜像队列,存在于多个节点,这样就可以实现 RabbitMQ 的 HA 高可用性。作用就是消息实体会主动在镜像节点之间实现同步,而不是像普通集群模式那样,在 consumer 消费数据时临时读取。
镜像模式配置非常简单,首先镜像模式是基于普通集群模式的,所以前面搭建的集群就是普通模式集群了。在搭建好的集群模式下,选择一个节点,通过命令或者MQ管理后台设置策略为镜像模式即可。
我们在前面的搭建的集群环境基础上,选择节点1进行设置:
docker exec -it myrabbit1 bash
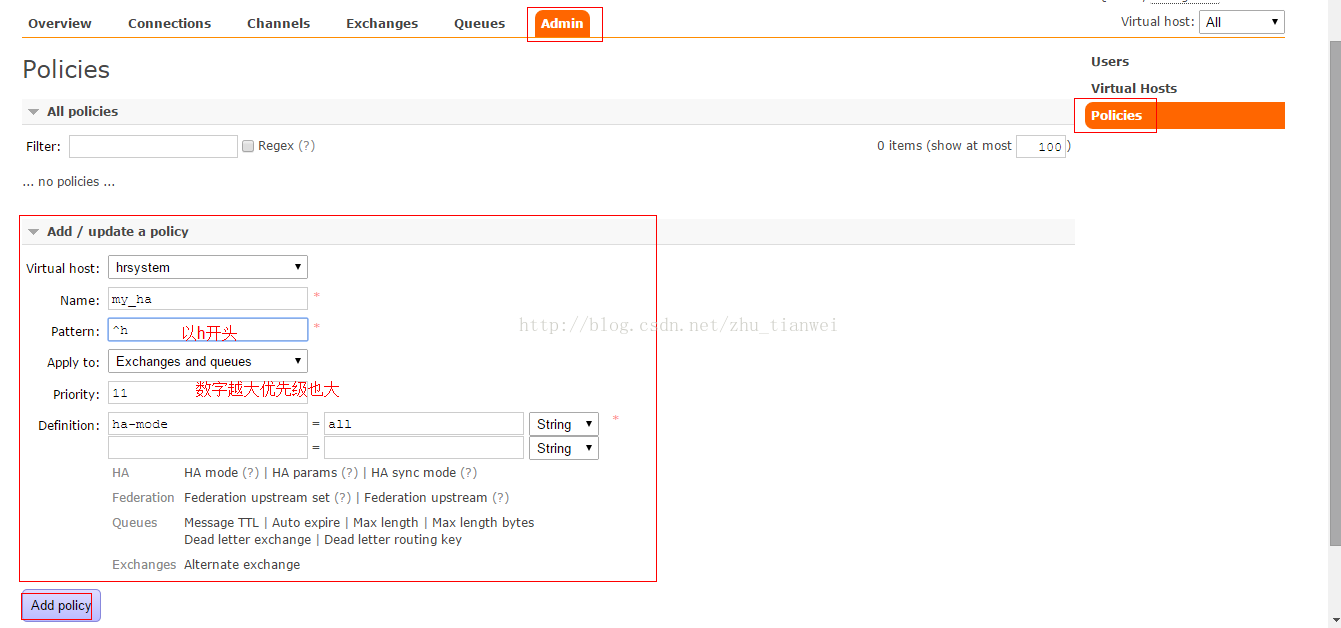
rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
exit
2
3
也可以通过MQ管理后台设置:
# 安装HAProxy
# 拉取镜像
docker pull haproxy
# 配置haproxy
在本地新增haproxy.cfg文件,内容如下
global
log 127.0.0.1 local0 info
log 127.0.0.1 local1 notice
daemon
maxconn 4096
defaults
log global
mode tcp
option tcplog
option dontlognull
retries 3
option abortonclose
maxconn 4096
timeout connect 5000ms
timeout client 3000ms
timeout server 3000ms
balance roundrobin
listen private_monitoring
bind 0.0.0.0:8100
mode http
option httplog
stats refresh 5s
stats uri /stats
stats realm Haproxy
stats auth admin:admin
listen rabbitmq_cluster
bind 0.0.0.0:8101
mode tcp
option tcplog
balance roundrobin
server rabbitmq1 172.100.100:5672 check inter 5000 rise 2 fall 3
server rabbitmq2 172.100.100:5672 check inter 5000 rise 2 fall 3
server rabbitmq3 172.100.100:5672 check inter 5000 rise 2 fall 3
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# 启动haproxy
docker run -d --name haproxy -p 8100:8100 -p 8101:8101 --ip=172.100.100.1 --net=rabbitmq-net -v /usr/local/haproxy/etc/haproxy.cfg:/usr/local/etc/haproxy/haproxy.cfg haproxy
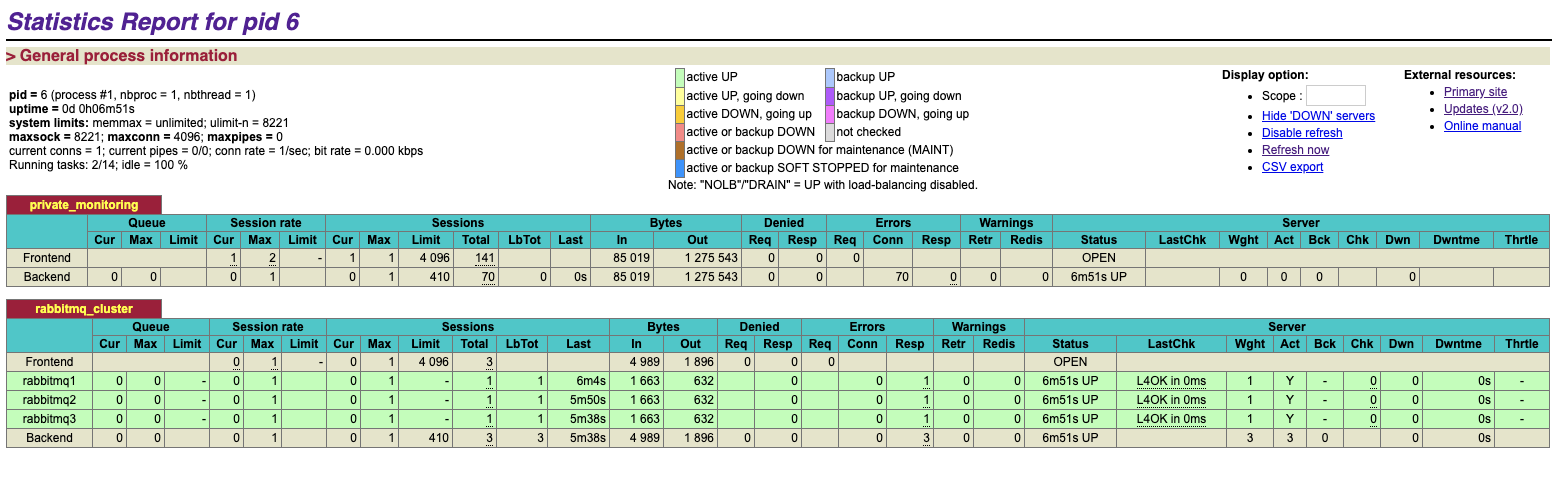
通过haproxy状态监控页面,就可以看到当前haproxy运行状态,如下图所示,我们添加的三个节点都正常在线:
到此,基于镜像队列的好可用RabbitMQ集群就算搭建完成。
# 总结
1. RabbitMQ集群同步的内部元数据有哪些?
- 队列元数据:队列名称和它的属性
- 交换器元数据:交换器名称、类型和属性
- 绑定元数据:一张简单的表格展示了如何将消息路由到队列
- vhost元数据:为vhost内的队列、交换器和绑定提供命名空间和安全属性
因此,当用户访问其中任何一个RabbitMQ节点时,通过rabbitmqctl查询到的queue/user/exchange/vhost等信息都是相同的。
2. 为何RabbitMQ集群仅采用元数据同步的方式?
存储空间:如果每个集群节点都拥有所有Queue的完全数据拷贝,那么每个节点的存储空间会非常大,集群的消息积压能力会非常弱(无法通过集群节点的扩容提高消息积压能力);
性能:消息的发布者需要将消息复制到每一个集群节点,对于持久化消息,网络和磁盘同步复制的开销都会明显增加。
3. 集群节点类型有哪些?
磁盘节点:将配置信息和元信息存储在磁盘上(单节点系统必须是磁盘节点,否则每次重启RabbitMQ之后所有的系统配置信息都会丢失)。
内存节点:将配置信息和元信息存储在内存中。性能是优于磁盘节点的。
RabbitMQ要求集群中至少有一个磁盘节点,当节点加入和离开集群时,必须通知磁盘节点(如果集群中唯一的磁盘节点崩溃了,则不能进行创建队列、创建交换器、创建绑定、添加用户、更改权限、添加和删除集群节点)。总之如果唯一磁盘的磁盘节点崩溃,集群是可以保持运行的,但不能更改任何东西。因此建议在集群中设置两个磁盘节点,只要一个可以,就能正常操作。