 读书笔记之《大型网站技术架构》
读书笔记之《大型网站技术架构》
- 不要企图去设计一个大型网站,架构是演变而来,而不是设计而来。
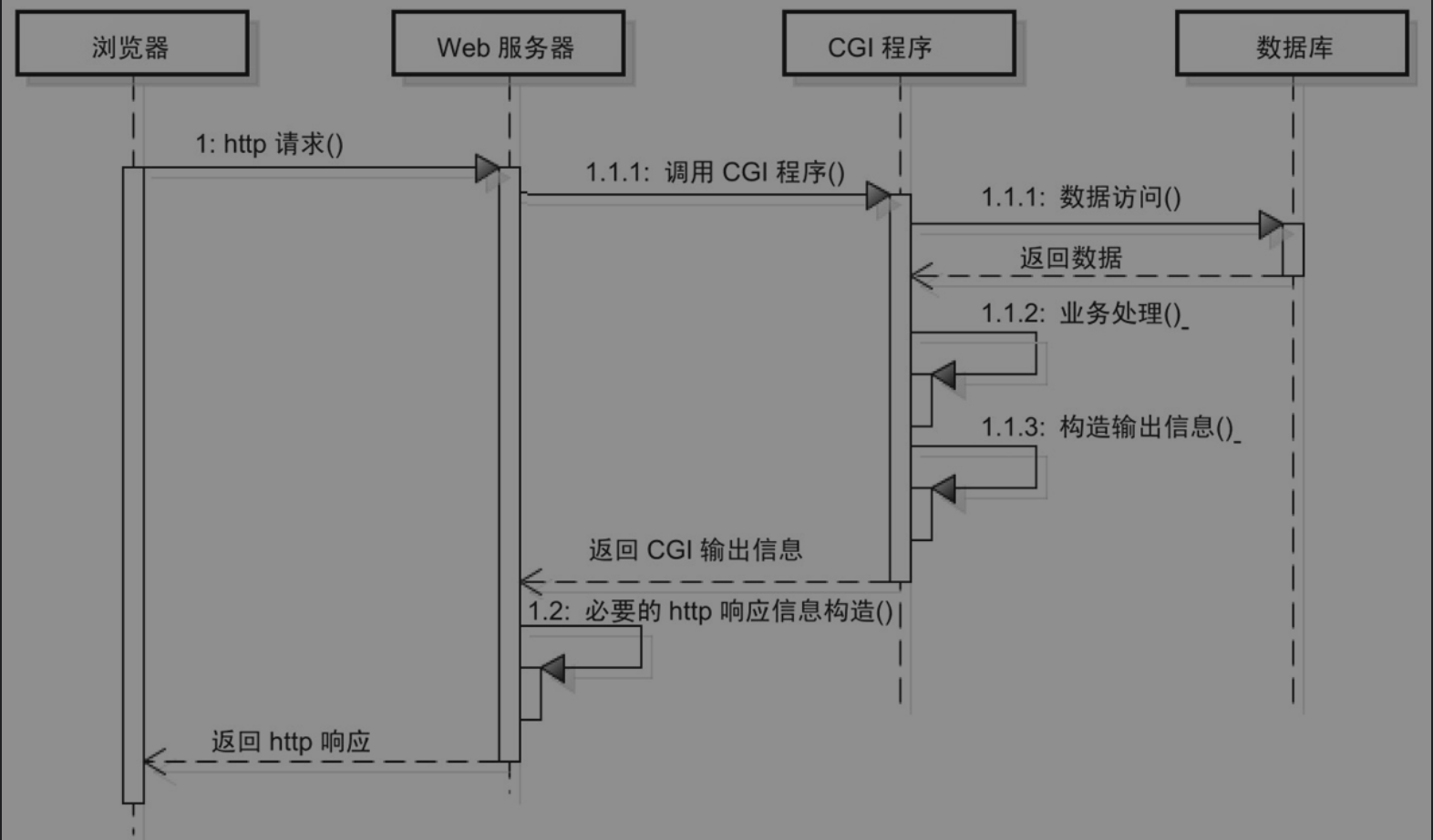
- 早期的Web服务器只简单地响应浏览器端的请求,返回静态的HTML。随着CGI(CommonGateway Interface,通用网关接口)技术的出现,Web服务端可以根据不同用户请求产生动态页面内容。
【业务拆分】将复杂而又庞大的业务拆分开来,形成多个规模较小的产品,独立开发、部署、维护,除了降低系统耦合度,也便于数据库业务分库。按业务对关系数据库进行拆分,技术难度相对较小,而效果又相对较好。
【分布式消息】利用消息队列机制,实现业务和业务、业务和服务之间的异步消息发送及低耦合的业务关系。
【分布式缓存】通过可伸缩的服务器集群提供大规模热点数据的缓存服务,是网站性能优化的重要手段。
【分布式配置】系统运行需要配置许多参数,如果这些参数需要修改,比如分布式缓存集群加入新的缓存服务器,需要修改应用程序客户端的缓存服务器列表配置,并重启应用程序服务器。分布式配置在系统运行期提供配置动态推送服务,将配置修改实时推送到应用系统,无需重启服务器。
【分布式文件】网站在线业务需要存储的文件大部分都是图片、网页、视频等比较小的文件,但是这些文件的数量非常庞大,而且通常都在持续增加,需要伸缩性设计比较好的分布式文件系统。
【领导的真谛】寻找一个值得共同奋斗的目标,营造一个让大家都能最大限度发挥自我价值的工作氛围。
一些企业喜欢挖优秀的人,而不是去把自己打造成一个培养优秀人才的地方。殊不知:是事情成就了人,而不是人成就了事。指望优秀的人来帮自己成事,不如做成一件事让自己和参与的人都变得优秀。
所谓问题,就是体验—期望,当体验不能满足期望,就会觉得出了问题。消除问题有两种手段:改善体验或者降低期望。降低期望只是回避了问题,而如果直面期望和体验之间的差距,就会发现问题所在,找到突破点。
经验教训:
- 代码提交前使用diff命令进行代码比较,确认没有提交不该提交的代码。
- 加强code review,代码在正式提交前必须被至少一个其他工程师做过codereview,并且共同承担因代码引起的故障责任。
不允许没有监控的系统上线
【CAP原理】认为,一个提供数据服务的存储系统无法同时满足数据一致性(Consistency)、数据可用性(Availibility)、分区耐受性(PatitionTolerance,系统具有跨网络分区的伸缩性)这三个条件。
网站不可用也被称作网站故障,业界通常用多少个9来衡量网站的可用性,如QQ的可用性是4个9,即QQ服务99.99%可用,这意味着QQ服务要保证其在所有运行时间中,只有0.01%的时间不可用,也就是一年中大约最多53分钟不可用。
网站不可用时间(故障时间)=故障修复时间点-故障发现(报告)时间点网站年度可用性指标=(1-网站不可用时间/年度总时间)×100%
对于大多数网站而言,2个9是基本可用,网站年度不可用时间小于88小时;3个9是较高可用,网站年度不可用时间小于9小时;4个9是具有自动恢复能力的高可用,网站年度不可用时间小于53分钟;5个9是极高可用性,网站年度不可用时间小于5分钟。
由于可用性影响因素很多,对于网站整体而言,达到4个9,乃至5个9的可用性,除了过硬的技术、大量的设备资金投入和工程师的责任心,还要有个好运气。

故障分的计算公式为:故障分=故障时间(分钟)× 故障权重
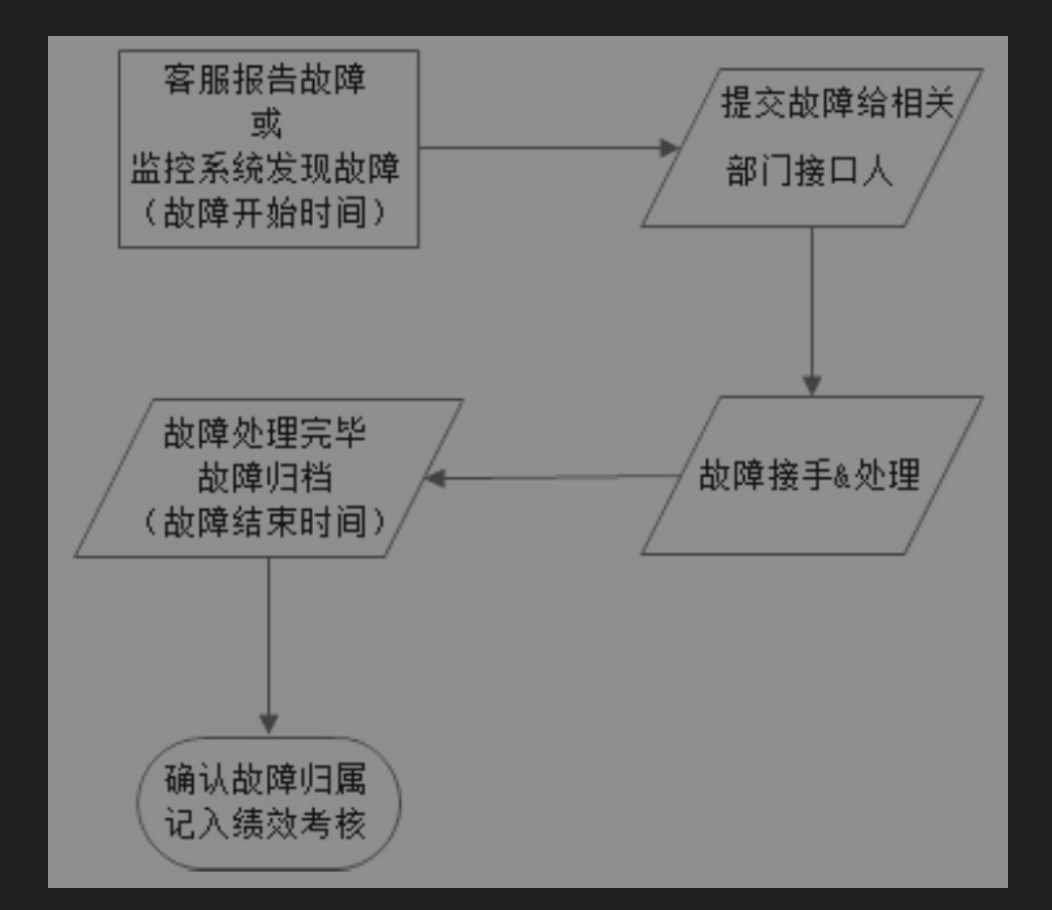
在年初或者考核季度的开始,会根据网站产品的可用性指标计算总的故障分,然后根据团队和个人的职责角色分摊故障分,这个可用性指标和故障分是管理预期。在实际发生故障的时候,根据故障分类和责任划分将故障产生的故障分分配给责任者承担。等年末或者考核季度末的时候,个人及团队实际承担的故障分如果超过了年初分摊的故障分,绩效考核就会受到影响。一个简化的故障处理流程如图5.1所示。
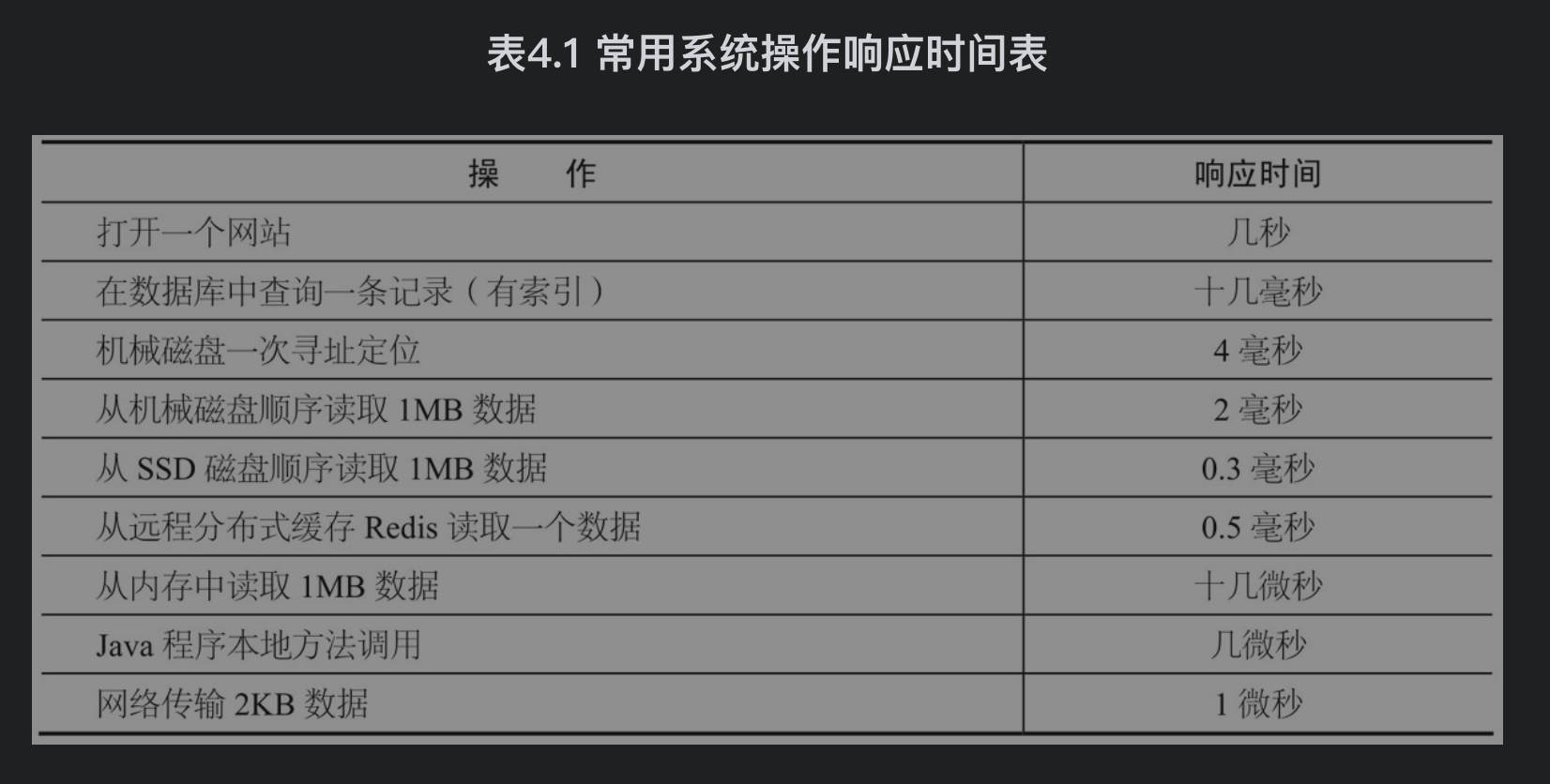
常用系统操作响应时间
多核CPU的情况下,完美情况是所有CPU都在使用,没有进程在等待处理,所以Load的理想值是CPU的数目。当Load值低于CPU数目的时候,表示CPU有空闲,资源存在浪费;当Load值高于CPU数目的时候,表示进程在排队等待CPU调度,表示系统资源不足,影响应用程序的执行性能。在Linux系统中使用top命令查看,该值是三个浮点数,表示最近1分钟,10分钟,15分钟的运行队列平均进程数。

系统运行时,要尽量减少那些开销很大的系统资源的创建和销毁,比如数据库连接、网络通信连接、线程、复杂对象等。从编程角度,资源复用主要有两种模式:单例(Singleton)和对象池(Object Pool)。