 大数据开发入门之hadoop介绍
大数据开发入门之hadoop介绍

Hadoop是一个由Apache基金会所开发的分布式系统基础架构,它可以使用户在不了解分布式底层细节的情况下开发分布式程序,充分利用集群的威力进行高速运算和存储。
# Hadoop架构
Hadoop有三个核心组件:
- **HDFS:**分布式文件系统
- **YARN:**资源管理调度系统
- MapReduce:分布式计算框架
# HDFS
HDFS(Hadoop Distributed File System)是可扩展、容错、高性能的分布式文件系统,可以被广泛的部署于廉价的PC上。对外部客户端而言,HDFS就像一个传统的分级文件系统,可以进行创建、删除、移动或重命名文件或文件夹等操作,与Linux文件系统类似。
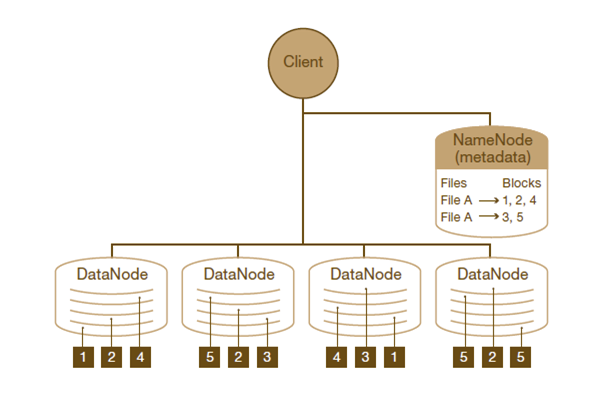
HDFS架构采用主从架构(master/slave),由一组特定的节点构建的,这些节点包括:
- 名称节点(NameNode),它在HDFS内部提供元数据服务;
- 第二名称节点(Secondary NameNode),名称节点的帮助节点,主要是为了整合元数据操作(不是名称节点的备份);
- 数据节点(DataNode),它为HDFS提供存储块;
# 名称节点(NameNode)
NameNode是整个文件系统的管理节点,也是HDFS的守护程序,存储在内存,管理数据映射,处理客户端的读写请求,对内存和I/O进行集中管理,管理HDFS的名称空间,会纪录所有的元数据分布存储的状态信息,比如文件是如何分割成数据块的,以及这些数据块被存储到哪些节点上。用户首先会访问Namenode,通过该总控节点获取文件分布的状态信息,找到文件分布到了哪些数据节点。不过这是个单点,发生故障将使集群崩溃。
NameNode中的信息虽然保存在内存中,但是也是可以持久化到磁盘上的。
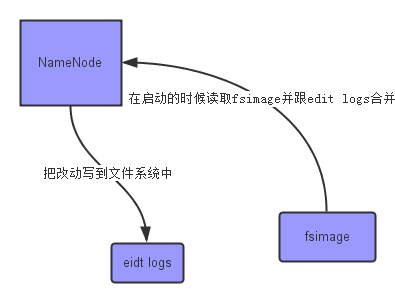
上面的这张图片展示了NameNode怎么把元数据保存到磁盘上的,这里有两个不同的文件:
- fsimage:它是在NameNode启动时对整个文件系统的快照
- editlogs:它是在NameNode启动后,对文件系统的改动序列
只有在NameNode重启时,edit logs才会合并到fsimage文件中,从而得到一个文件系统的最新快照。但是在产品集群中NameNode是很少重启的,这也意味着当NameNode运行了很长时间后,edit logs文件会变得很大。在这种情况下就会出现下面一些问题:
- edit logs文件会变的很大,怎么去管理这个文件是一个挑战。
- NameNode的重启会花费很长时间,因为有很多改动要合并到fsimage文件上。
Secondary NameNode就是来帮助解决上述问题的,接着往下看,先了解一下Secondary NameNode。
# 第二名称节点(Secondary NameNode)
第二名称节点也称辅助名称节点,监控HDFS状态的辅助后台程序,可以保存名称节点的副本,它与NameNode进行通讯,定期保存HDFS元数据快照,NameNode故障可以作为备用NameNode使用,目前还不能自动切换。
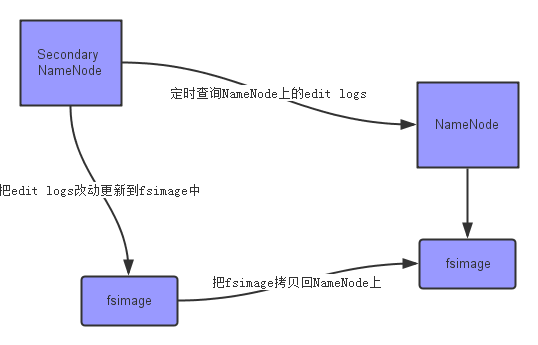
上面的图片展示了Secondary NameNode是怎么工作的:
- 首先,它定时到NameNode去获取edit logs,并更新到fsimage上;
- 一旦它有了新的fsimage文件,它将其拷贝回NameNode中;
- NameNode在下次重启时会使用这个新的fsimage文件,从而减少重启的时间;
现在,我们明白了Secondary NameNode所做的不过是在文件系统中设置一个检查点来帮助NameNode更好的工作,它不是要取代掉NameNode也不是NameNode的备份。
# 数据节点(DataNode)
DataNode是slave节点,存储在磁盘,负责存储客户端发来的数据块,执行数据块的读写操作并提供检索等服务。
在HDFS中,块(block)是最基本的存储单位,HDFS将每个文件分成一系列较小但仍然较大的块(默认的块大小等于128 MB)。每个块被冗余地存储在三个DataNode上,以实现容错(注:每个文件的副本数量是可配置的)。
# YARN
YAEN(Yet Another Resource Negotiator),资源管理调度系统。YARN主要由ResourceManager、NodeManager、ApplicationMaster和Container等组件构成。
# ResourceManager
ResourceManager是master上的进程,负责整个分布式系统的资源管理和调度。他会处理来自client端的请求(包括提交作业/杀死作业);启动/监控Application Master;监控NodeManager的情况,比如可能挂掉的NodeManager。
# NodeManager
相对应的,NodeManager时处在slave节点上的进程,他只负责当前slave节点的资源管理和调度,以及task的运行。他会定期向ResourceManager回报资源/Container的情况(heartbeat);接受来自ResourceManager对于Container的启停命令。
# Application Master
每一个提交到集群的作业都会有一个与之对应的Application Master来负责应用程序的管理。他负责进行数据切分;为当前应用程序向ResourceManager去申请资源(也就是Container),并分配给具体的任务;与NodeManager通信,用来启停具体的任务,任务运行在Container中;而任务的监控和容错也是由Application Master来负责的。
# Container
那么container又是什么呢?它包含了Application Master向ResourceManager申请的计算资源,比如说CPU/内存的大小,以及任务运行所需的环境变量和队任务运行情况的描述。AM也是在container上运行的,不过AM的container是RM申请的。
# 工作流程

- Client向ResourceManager提交作业(可以是Spark/Mapreduce作业);
- ResourceManager会为这个作业分配一个container;
- ResourceManager与NodeManager通信,要求NodeManger在刚刚分配好的container上启动应用程序的Application Master;
- Application Master先去向ResourceManager注册,而后ResourceManager会为各个任务申请资源,并监控运行情况;
- Application Master采用轮询(polling)方式向ResourceManager申请并领取资源(通过RPC协议通信);
- Application Manager申请到了资源以后,就和NodeManager通信,要求NodeManager启动任务;
- 最后,NodeManger启动作业对应的任务。
# Mapreduce
MapReduce是一种编程模型,用于大规模数据集的并行运算。Map(映射)和Reduce(化简),采用分而治之思想,先把任务分发到集群多个节点上,并行计算,然后再把计算结果合并,从而得到最终计算结果。
MapReduce的计算流程:
输入 --> map --> shuffle --> reduce -->输出
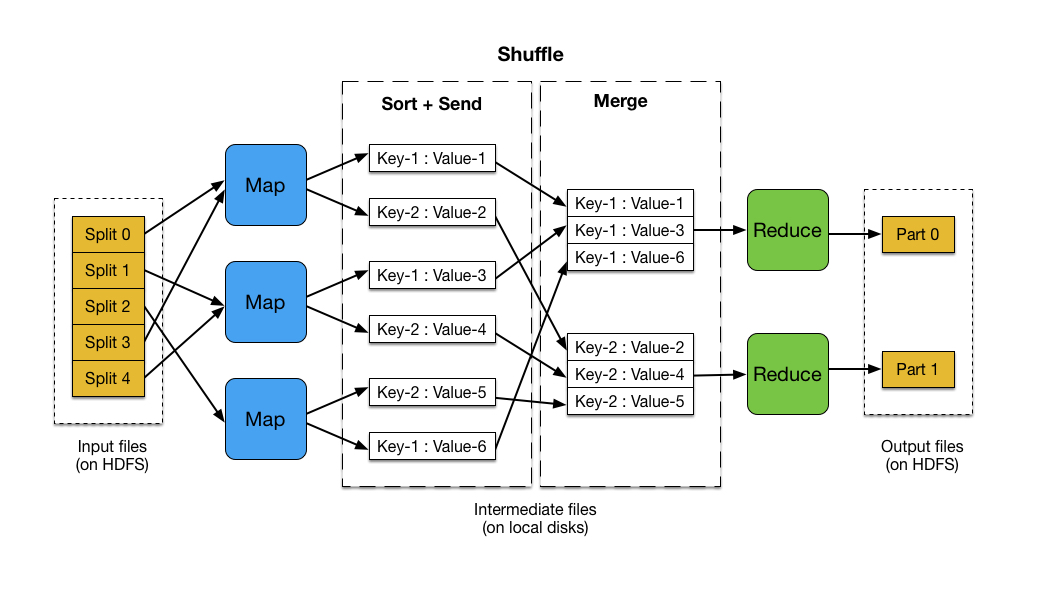
流程说明如下:
- 输入文件分片,每一片都由一个MapTask来处理;
- Map输出的中间结果会先放在内存缓冲区中,这个缓冲区的大小默认是100M,当缓冲区中的内容达到80%时(80M)会将缓冲区的内容写到磁盘上。也就是说,一个map会输出一个或者多个这样的文件,如果一个map输出的全部内容没有超过限制,那么最终也会发生这个写磁盘的操作,只不过是写几次的问题;
- 从缓冲区写到磁盘的时候,会进行分区并排序,分区指的是某个key应该进入到哪个分区,同一分区中的key会进行排序,如果定义了Combiner的话,也会进行combine操作;
- 如果一个map产生的中间结果存放到多个文件,那么这些文件最终会合并成一个文件,这个合并过程不会改变分区数量,只会减少文件数量。例如,假设分了3个区,4个文件,那么最终会合并成1个文件,3个区;
- 以上只是一个map的输出,接下来进入reduce阶段,每个reducer对应一个ReduceTask,在真正开始reduce之前,先要从分区中抓取数据;
- 相同的分区的数据会进入同一个reduce。这一步中会从所有map输出中抓取某一分区的数据,在抓取的过程中伴随着排序、合并;
- reduce输出;
通俗说MapReduce是一套从海量源数据提取分析元素最后返回结果集的编程模型,将文件分布式存储到硬盘是第一步,而从海量数据中提取分析我们需要的内容就是MapReduce做的事了。
# Hadoop生态圈
广义上来讲,我们经常提到的hadoop其实是指hadoop生态圈,是由很多工具组成的庞大的大数据处理工具链。
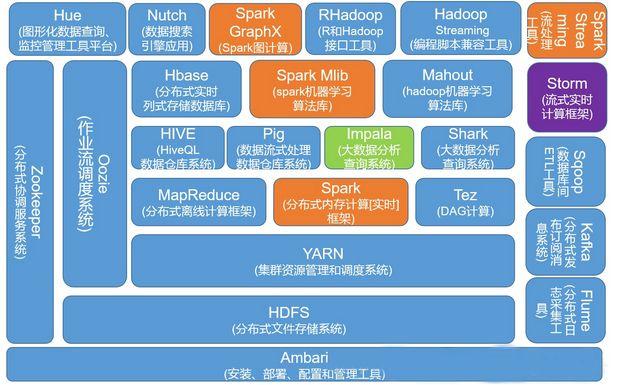
整个hadoop生态圈,涉及到30多种工具和应用,十分庞大,要想全部掌握,确实有点困难。关于hadoop生态圈组成部分,不在本文讨论范畴,大家可以自行百度。