 Redis集群及高可用实现
Redis集群及高可用实现
Redis集群方式共有三种:主从模式,哨兵模式,cluster(集群)模式。
# 主从模式
关于主从模式参考之前的文章:Redis主从模式搭建及应用
# Sentinel(哨兵)
Sentinel(哨兵模式)是Redis官方推荐的高可用性(HA)解决方案,当用Redis做Master-slave的高可用方案时,假如master宕机了,Redis本身(包括它的很多客户端)都没有实现自动进行主备切换,而Redis-sentinel本身也是一个独立运行的进程,它能监控多个master-slave集群,发现master宕机后能进行自动切换。
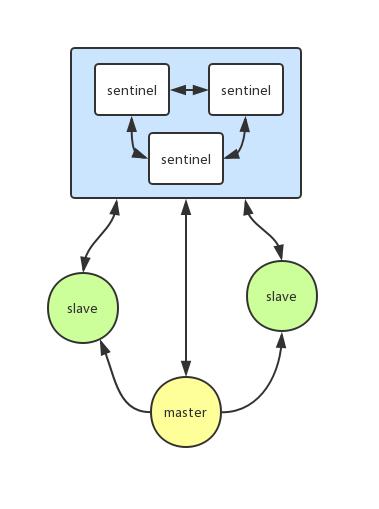
# Redis哨兵主要功能
- 监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
- 提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
- 自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器。
# Redis哨兵配置
哨兵相关配置文件:sentinel.conf(同redis配置文件在同一个路径下)
配置实例(仅供参考):
port 26379 #端口
daemonize yes #守护进程
pidfile /usr/local.redis/redis-sentinel26379.pid #pid
dir /usr/local/redis #工作目录
logfile "/usr/local/redis/log/sentinel_26379.log" #日志文件
sentinel monitor mymaster 127.0.0.1 6379 2 #sentinel主节点的名称mymaster 主节点 127.0.0.1 6379,2个sentinel检测到主节点有问题就进行故障转移
sentinel down-after-milliseconds mymaster 30000 #30秒ping不同就认为主节点有问题
sentinel parallel-syncs mymaster 1 #老的slave或者新的master进行复制,最多可以有多少个slave同时对新的master进行 同步,推荐1
sentinel failover-timeout mymaster 180000 #故障转移时间
2
3
4
5
6
7
8
9
# 启动sentinel
src/redis-sentinel sentinel.conf
# 查看sentinel状况
redis-cli -p 26379 info
返回结果示例:
gitlib@devops:/usr/local/redis$ src/redis-cli -p 26381 info
....
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=127.0.0.1:6381,slaves=2,sentinels=3
2
3
4
5
6
7
8
9
# Redis哨兵实现流程
- Sentinel集群通过配置文件发现master,启动时会监控master;
- 向master发送info命令,获取其所有slave节点;
- Sentinel集群向Redis主从服务器发送hello信息(心跳),包括Sentinel本身的ip、端口、id等内容,以此来向其他Sentinel宣告自己的存在;
- Sentinel集群通过订阅接收其他Sentinel发送的hello信息,以此来发现监视同一个主服务器的其他Sentinel;集群之间会互相创建命令连接用于通信,因为已经有主从服务器作为发送和接收hello信息的中介,Sentinel之间不会创建订阅连接;
- Sentinel集群使用ping命令来检测实例的状态,如果在指定的时间内(down-after-milliseconds)没有回复或则返回错误的回复,那么该实例被判为下线;
- 当failover主备切换被触发后,并不会马上进行,还需要Sentinel中的大多数sentinel授权后才可以进行failover,即进行failover的Sentinel会去获得指定quorum个的Sentinel的授权,成功后进入ODOWN状态。如在5个Sentinel中配置了2个quorum,等到2个Sentinel认为master死了就执行failover。
- Sentinel向选为master的slave发送 SLAVEOF NO ONE 命令,选择slave的条件是Sentinel首先会根据slaves的优先级来进行排序,优先级越小排名越靠前。如果优先级相同,则查看复制的下标,哪个从master接收的复制数据多,哪个就靠前。如果优先级和下标都相同,就选择进程ID较小的。
- Sentinel被授权后,它将会获得宕掉的master的一份最新配置版本号(config-epoch),当failover执行结束以后,这个版本号将会被用于最新的配置,通过广播形式通知其它sentinel,其它的sentinel则更新对应master的配置。
# Redis哨兵的高可用
当主节点出现故障时,由Redis Sentinel自动完成故障发现和转移,并通知应用方,实现高可用性。
- 哨兵机制建立了多个哨兵节点(进程),共同监控数据节点的运行状况。
- 同时哨兵节点之间也互相通信,交换对主从节点的监控状况。
- 每隔1秒每个哨兵会向整个集群:Master主服务器+Slave从服务器+其他Sentinel(哨兵)进程,发送一次ping命令做一次心跳检测。
这个就是哨兵用来判断节点是否正常的重要依据,涉及两个新的概念**:主观下线和客观下线。**
- **主观下线:**一个哨兵节点判定主节点down掉是主观下线。
- **客观下线:**只有半数哨兵节点都主观判定主节点down掉,此时多个哨兵节点交换主观判定结果,才会判定主节点客观下线。
基本上哪个哨兵节点最先判断出这个主节点客观下线,就会在各个哨兵节点中发起投票机制Raft算法(选举算法),最终被投为领导者的哨兵节点完成主从自动化切换的过程。
# Redis Cluster
虽然主从复制和哨兵模式完美的解决了Redis的单机问题,但是Redis仍然存在着以下两个问题:
- 所有的写操作都集中到主服务器上,主服务器CPU压力比较大;
- 不管是主服务器还是从服务器,它们都同样保存了redis的所有数据,随着数据越来越多,可能会出现内存不够用的问题;
在redis集群中,key只能保存在按照某种规律计算得到的节点上,对该key的读取和更新也只能在该节点进行。比如redis集群一共有6个节点,现在我想执行 set name hello,这个key为name,常见的某种规律有哈希取余"name".hashcode() % 6 + 1得到节点的位置为4,所以就放在第四个的位置上,以后不管我是读取还是更新还是删除,我都到第四个节点上。如此一来,便完美解决了上述两个问题。
# Redis 分区方案
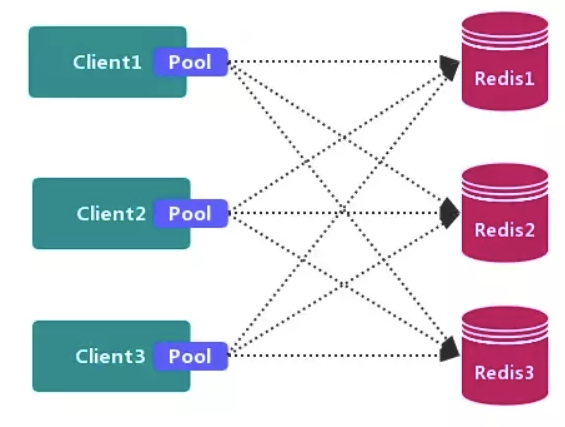
# 客户端分区方案
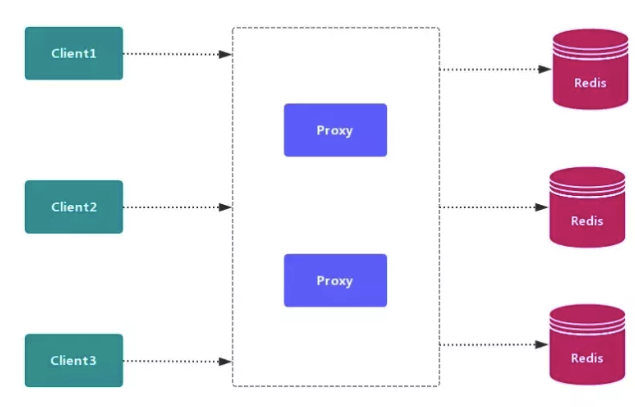
# 代理分区方案
指在客户端和服务器之间加了一层代理层,客户端的命令先到代理层,代理层进行计算,再分配到它对应的节点上;这种方法挺好的,节点数发生变化,只需要修改代理层的计算算法即可,但是需要多一层转发,需要一定的耗时。
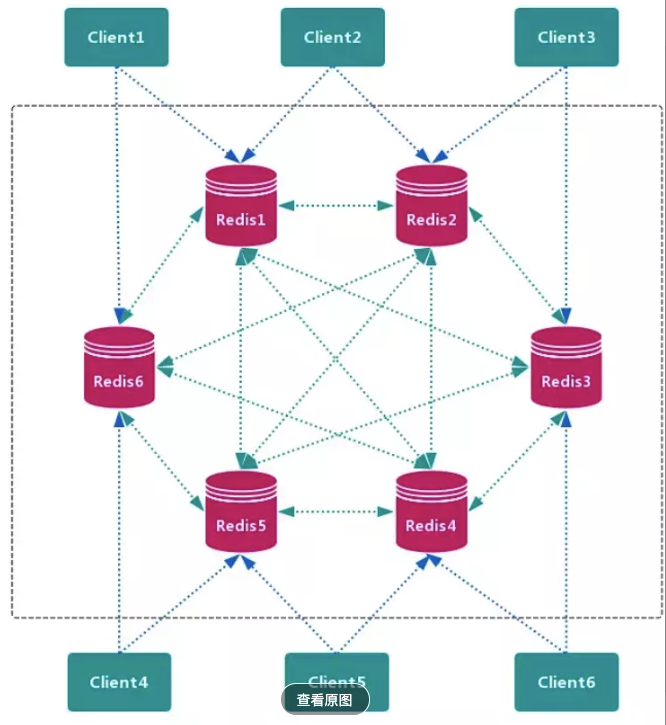
# 查询路由方案
节点之间早就约定好哪些key是属于自己,哪些key是属于其它节点;客户端最开始随机把命令发给某个节点,节点计算并查看这个key是否属于自己的,如果是自己的就进行处理,并把结果发回去;如果是其它节点的,就会把那个节点的信息(ip + 地址)转发给客户端,让客户端重定向,这么一说感觉是有点像http协议中的3XX状态码。Redis Cluster`就是基于查询路由方案。
# 哈希槽
在Redis Cluster中,约定了有16384(2^14)个槽,我们对key进行CRC16(key) & 16383计算后会得到这个key属于哪个槽,这16384个槽在集群创建之初,会自动或者手动的分配到不同的节点中,即key -> slot -> node。添加或者删除新的节点的时候,只需要对对应的槽进行重新分配即可。
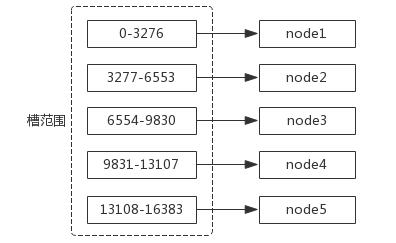
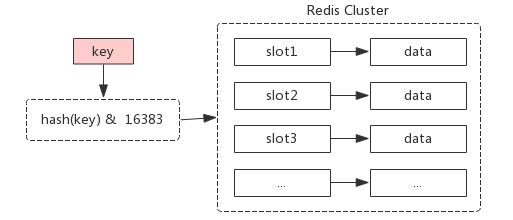
# 基本架构
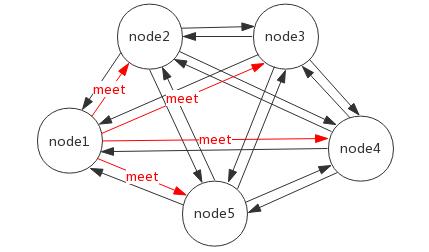
节点:Redis Cluster 中会有多个节点,节点之间是相互通信的,且每个节点都负责读写。
meet 操作(gossip 协议):点之间相互通信的基础。假如现在有 5 个节点,node1 节点对 node2、node3、node4、node5 节点分别发送了一个 meet 操作,node2 等节点会各自返回一个 pong 命令(表示 Redis 服务运行正常),其他节点可以自动找到,最终所有节点都可以相互通信。
分配槽:需要给节点分配虚拟槽, 对于客户端来说,只需要计算 slot = hash(key) %16383。
# 创建集群
# 准备节点
一个高可用的redis集群至少要有6个节点
# redis-6379.conf
port 6379
daemonize yes
protected-mode no
logfile "6379.log"
dbfilename "dump-6379.rdb"
cluster-enabled yes # 开启集群
cluster-node-timeout 15000 #节点超时时间,15s
cluster-config-file "nodes-6379.conf" #集群内部配置文件
# redis-6380.conf
port 6380
daemonize yes
protected-mode no
logfile "6380.log"
dbfilename "dump-6380.rdb"
cluster-enabled yes # 开启集群
cluster-node-timeout 15000 #节点超时时间,15s
cluster-config-file "nodes-6380.conf" #集群内部配置文件
# redis-6381.conf
port 6381
daemonize yes
protected-mode no
logfile "6381.log"
dbfilename "dump-6381.rdb"
cluster-enabled yes # 开启集群
cluster-node-timeout 15000 #节点超时时间,15s
cluster-config-file "nodes-6381.conf" #集群内部配置文件
# redis-6382.conf
port 6382
daemonize yes
protected-mode no
logfile "6382.log"
dbfilename "dump-6382.rdb"
cluster-enabled yes # 开启集群
cluster-node-timeout 15000 #节点超时时间,15s
cluster-config-file "nodes-6382.conf" #集群内部配置文件
# redis-6383.conf
port 6383
daemonize yes
protected-mode no
logfile "6383.log"
dbfilename "dump-6383.rdb"
cluster-enabled yes # 开启集群
cluster-node-timeout 15000 #节点超时时间,15s
cluster-config-file "nodes-6383.conf" #集群内部配置文件
# redis-6384.conf
port 6384
daemonize yes
protected-mode no
logfile "6384.log"
dbfilename "dump-6384.rdb"
cluster-enabled yes # 开启集群
cluster-node-timeout 15000 #节点超时时间,15s
cluster-config-file "nodes-6384.conf" #集群内部配置文件
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
6个节点启动成功后,我们可以在redis目录下看到生成的cluster-config-file文件:
gitlib@devops:/usr/local/redis/data$ ls
dump_6379.rdb dump_6381.rdb dump_6383.rdb dump.rdb nodes-6380.conf nodes-6382.conf nodes-6384.conf
dump_6380.rdb dump_6382.rdb dump_6384.rdb nodes-6379.conf nodes-6381.conf nodes-6383.conf
2
3
# 节点握手
打开客户端进入6379,然后依次运行cluster meet 127.0.0.1 6380到cluster meet 127.0.0.1 6384
cluster meet 两个节点互相感知对方存在,发起节点发送发送Gossip协议中的meet消息给接收节点,接收节点收到meet消息后,保存发起节点的信息,然后通过返回pong消息把自己的信息也返回回去,之后两个节点会定期ping/pong进行节点通信。可以把它理解为把某个节点拉到一个集群里面,如果把其它节点也拉进来以后,集群里面的节点两两之间都会互相握手。等所有节点都拉到集群以后,可以执行cluster nodes来查看集群中节点间的关系。
127.0.0.1:6379> cluster nodes
1a7c672c3c271f69182ec99b94bfbdf61ec5eed9 127.0.0.1:6379 myself,master - 0 0 1 connected
119f54da3e7610fce43521f400154458da4ee9fb 127.0.0.1:6380 master - 0 1540711563919 0 connected
8a43c4b0717f5d7403b6b457b6f6cb4177c8302f 127.0.0.1:6381 master - 0 1540711564922 2 connected
2cadf753b091a6957f282d29222faabc4b5ec852 127.0.0.1:6382 master - 0 1540711562919 3 connected
564d273e647be63fbd3aaa14f0d6c9e819387ecd 127.0.0.1:6383 master - 0 1540711565924 4 connected
b58e0d12543d2b333cdf08f5b8f5fd9db1d62732 127.0.0.1:6384 master - 0 1540711561916 5 connected
2
3
4
5
6
7
# 分配槽
以上只是建立了一个集群,但是其实集群还不能工作,可以用cluster info来查看集群状态:
127.0.0.1:6379> cluster info
cluster_state:fail
cluster_slots_assigned:0
cluster_slots_ok:0
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:0
cluster_current_epoch:5
cluster_my_epoch:1
cluster_stats_messages_sent:288
cluster_stats_messages_received:288
2
3
4
5
6
7
8
9
10
11
12
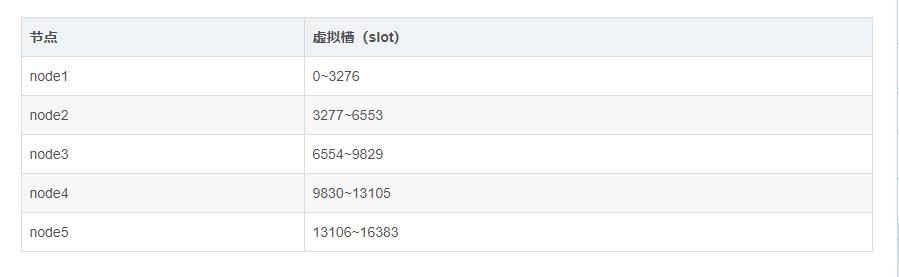
可以看到此时集群的状态是fail,失败的,我们需要把这16383个槽分出去,集群才能正常工作,分配槽的命令如下:
src/redis-cli -p 6379 cluster addslots {0..5461}
src/redis-cli -p 6380 cluster addslots {5462..10922}
src/redis-cli -p 6381 cluster addslots {10923..16383}
2
3
这样子就把所有的槽都分出去了,但是只用到了三个节点,剩下三个节点我们可以作为从节点,可以使用cluster replicate 主节点id来把某个节点挂为某个节点的从节点。
127.0.0.1:6382> cluster replicate 2cadf753b091a6957f282d29222faabc4b5ec852
127.0.0.1:6383> cluster replicate 564d273e647be63fbd3aaa14f0d6c9e819387ecd
127.0.0.1:6384> cluster replicate b58e0d12543d2b333cdf08f5b8f5fd9db1d62732
2
3
最后我们来看一下节点状态:
127.0.0.1:6379> cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:5
cluster_my_epoch:2
cluster_stats_messages_sent:17051
cluster_stats_messages_received:17051
2
3
4
5
6
7
8
9
10
11
12
再来查看一下节点关系:
127.0.0.1:6379> cluster nodes
119f54da3e7610fce43521f400154458da4ee9fb 127.0.0.1:6380 master - 0 1567431382368 1 connected 5462-10922
2cadf753b091a6957f282d29222faabc4b5ec852 127.0.0.1:6382 slave 1a7c672c3c271f69182ec99b94bfbdf61ec5eed9 0 1567431380866 3 connected
8a43c4b0717f5d7403b6b457b6f6cb4177c8302f 127.0.0.1:6381 master - 0 1567431382368 4 connected 10923-16383
b58e0d12543d2b333cdf08f5b8f5fd9db1d62732 127.0.0.1:6384 slave 8a43c4b0717f5d7403b6b457b6f6cb4177c8302f 0 1567431381366 4 connected
1a7c672c3c271f69182ec99b94bfbdf61ec5eed9 127.0.0.1:6379 myself,master - 0 0 2 connected 0-5461
564d273e647be63fbd3aaa14f0d6c9e819387ecd 127.0.0.1:6383 slave 119f54da3e7610fce43521f400154458da4ee9fb 0 1567431381868 5 connected
2
3
4
5
6
7
节点id,节点ip/端口,是否是主节点,节点的槽位分配一览无余。至此,一个完整的redis cluster集群创建成功。
# 测试
现在来做一个实例,打开redis-cli,连接6379,如果处理一个不属于这个节点的key:
127.0.0.1:6379> set name gitlib
(error) MOVED 5798 127.0.0.1:6380
2
可以看到节点6379返回一个重定向指令,name这个key的槽为5798,这个槽在139.199.168.61:6380这台服务器上。我们再去6380试试,可以看到可以正常处理。
127.0.0.1:6379> set name2 gitlib
OK
2
如果你想客户端自己帮我们重定向,可以在启动客户端的时候 加上 -c:
gitlib@devops:/usr/local/redis$ src/redis-cli -c
127.0.0.1:6379> set name gitlib
-> Redirected to slot [5798] located at 127.0.0.1:6380
OK
127.0.0.1:6380>
2
3
4
5
# 优缺点
# 优点
- 无中心架构;
- 数据按照 slot 存储分布在多个节点,节点间数据共享,可动态调整数据分布;
- 可扩展性:可线性扩展到 1000 多个节点,节点可动态添加或删除;
- 高可用性:部分节点不可用时,集群仍可用。通过增加 Slave 做 standby 数据副本,能够实现故障自动 failover,节点之间通过 gossip 协议交换状态信息,用投票机制完成 Slave 到 Master 的角色提升;
- 降低运维成本,提高系统的扩展性和可用性。
# 缺点
Client 实现复杂,驱动要求实现 Smart Client,缓存 slots mapping 信息并及时更新,提高了开发难度,客户端的不成熟影响业务的稳定性。目前仅 JedisCluster 相对成熟,异常处理部分还不完善,比如常见的“max redirect exception”。
节点会因为某些原因发生阻塞(阻塞时间大于 clutser-node-timeout),被判断下线,这种 failover 是没有必要的。
数据通过异步复制,不保证数据的强一致性。
多个业务使用同一套集群时,无法根据统计区分冷热数据,资源隔离性较差,容易出现相互影响的情况。
Slave 在集群中充当“冷备”,不能缓解读压力,当然可以通过 SDK 的合理设计来提高 Slave 资源的利用率。
Key 批量操作限制,如使用 mset、mget 目前只支持具有相同 slot 值的 Key 执行批量操作。对于映射为不同 slot 值的 Key 由于 Keys 不支持跨 slot 查询,所以执行 mset、mget、sunion 等操作支持不友好。
Key 事务操作支持有限,只支持多 key 在同一节点上的事务操作,当多个 Key 分布于不同的节点上时无法使用事务功能。
Key 作为数据分区的最小粒度,不能将一个很大的键值对象如 hash、list 等映射到不同的节点。
不支持多数据库空间,单机下的 redis 可以支持到 16 个数据库,集群模式下只能使用 1 个数据库空间,即 db 0。
复制结构只支持一层,从节点只能复制主节点,不支持嵌套树状复制结构。
避免产生 hot-key,导致主库节点成为系统的短板。
避免产生 big-key,导致网卡撑爆、慢查询等。
重试时间应该大于 cluster-node-time 时间。
Redis Cluster 不建议使用 pipeline 和 multi-keys 操作,减少 max redirect 产生的场景。
# 总结
主从复制是为了数据备份,哨兵是为了高可用,Redis主服务器挂了哨兵可以切换,集群则是因为单实例能力有限,搞多个分散压力,简短总结如下:
- 主从模式:读写分离,备份,一个Master可以有多个Slaves;
- 哨兵sentinel:监控,自动转移,哨兵发现主服务器挂了后,就会从slave中重新选举一个主服务器;
- 集群:为了解决单机Redis容量有限的问题,将数据按一定的规则分配到多台机器,内存/QPS不受限于单机,可受益于分布式集群高扩展性。