 ELK日志分析系统入门
ELK日志分析系统入门
# ELK架构的分类
ELK是一套应用组件,由Elasticsearch、Logstash和Kibana三部分组件组成,简称ELK;它是一套开源免费、功能强大的日志分析管理系统。ELK可以将我们的系统日志、网站日志、应用系统日志等各种日志进行收集、过滤、清洗,然后进行集中存放并可用于实时检索、分析。
- Elasticsearch :分布式搜索引擎。具有高可伸缩、高可靠、易管理等特点。可以用于全文检索、结构化检索和分析,并能将这三者结合起来。Elasticsearch 基于 Lucene 开发,现在使用最广的开源搜索引擎之一,Wikipedia 、StackOverflow、Github 等都基于它来构建自己的搜索引擎。
- Logstash :数据收集处理引擎。支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储以供后续使用。
- Kibana :可视化化平台。它能够搜索、展示存储在 Elasticsearch 中索引数据。使用它可以很方便的用图表、表格、地图展示和分析数据。
# 最简单的ELK架构
此架构主要是将Logstash部署在各个节点上搜集相关日志、数据,并经过分析、过滤后发送给远端服务器上的Elasticsearch进行存储。Elasticsearch再将数据以分片的形式压缩存储,并提供多种API供用户查询、操作。用户可以通过Kibana Web直观的对日志进行查询,并根据需求生成数据报表。
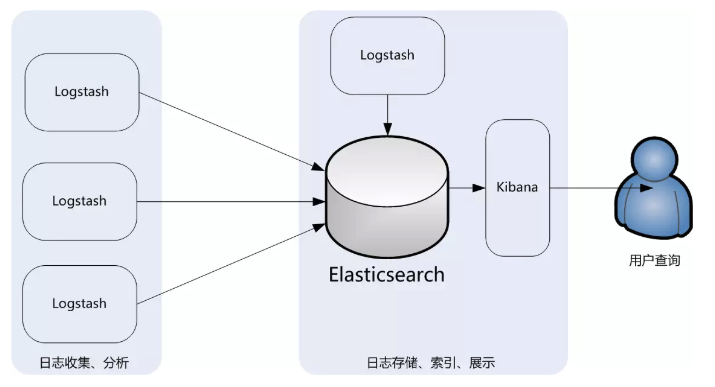
此架构的优点是搭建简单,易于上手。缺点是Logstash消耗系统资源比较大,运行时占用CPU和内存资源较高。另外,由于没有消息队列缓存,可能存在数据丢失的风险,适合于数据量小的环境使用。
# 引入Kafka的典型ELK架构
为保证日志传输数据的可靠性和稳定性,引入Kafka作为消息缓冲队列,位于各个节点上的Logstash Agent(一级Logstash,主要用来传输数据)先将数据传递给消息队列,接着,Logstash server(二级Logstash,主要用来拉取消息队列数据,过滤并分析数据)将格式化的数据传递给Elasticsearch进行存储。最后,由Kibana将日志和数据呈现给用户。由于引入了Kafka缓冲机制,即使远端Logstash server因故障停止运行,数据也不会丢失,可靠性得到了大大的提升。
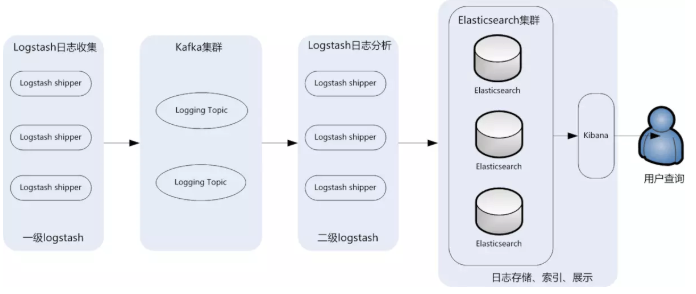
该架构优点在于引入了消息队列机制,提升日志数据的可靠性,但依然存在Logstash占用系统资源过多的问题,在海量数据应用场景下,可能会出现性能瓶颈。
# FileBeats+Kafka+ELK集群架构
该架构从上面架构基础上改进而来的,主要是将前端收集数据的Logstash Agent换成了filebeat,消息队列使用了kafka集群,然后将Logstash和Elasticsearch都通过集群模式进行构建,完整架构如图所示:
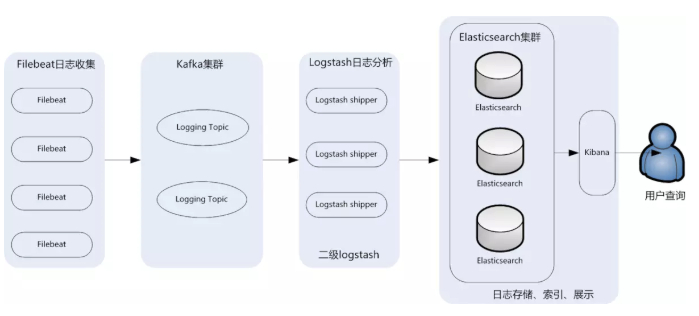
日志采集器Logstash其功能虽然强大,但是它依赖java、在数据量大的时候,Logstash进程会消耗过多的系统资源,这将严重影响业务系统的性能,而filebeat就是一个完美的替代者,它基于Go语言没有任何依赖,配置文件简单,格式明了,同时filebeat比logstash更加轻量级,所以占用系统资源极少,非常适合安装在生产机器上。这就是推荐使用filebeat,也是 ELK Stack 在 Agent 的第一选择。
此架构适合大型集群、海量数据的业务场景,它通过将前端Logstash Agent替换成filebeat,有效降低了收集日志对业务系统资源的消耗。同时,消息队列使用kafka集群架构,有效保障了收集数据的安全性和稳定性,而后端Logstash和Elasticsearch均采用集群模式搭建,从整体上提高了ELK系统的高效性、扩展性和吞吐量。我所在的项目组采用的就是这套架构,由于生产所需的配置较高,且涉及较多持久化操作,采用的都是性能高配的云主机搭建方式而非时下流行的容器搭建。
# FileBeat服务搭建
日志采集器选择了Filebeat而不是Logstash,是由于 Logstash 是跑在 JVM 上面,资源消耗比较大,后来作者用 GO 写了一个功能较少但是资源消耗也小的轻量级的 Agent 叫 Logstash-forwarder,后来改名为FileBeat。
- filebeat.yml配置
最核心的部分在于FileBeat配置文件的配置,需要指定paths(日志文件路径),fileds(日志主题),hosts(kafka主机ip和端口),topic(kafka主题),version(kafka的版本),drop_fields(舍弃不必要的字段),name(本机IP)
filebeat.inputs:
- input_type: log
paths:
- /var/log/nginx/*.log
json.keys_under_root: true
tags: ["nginx-accesslog"]
#================================ kafka output ===============================
output.kafka:
hosts: ["192.168.1.108:9092"]
topic: "nginx-log"
required_acks: 1
2
3
4
5
6
7
8
9
10
11
12
- 常用运维指令
- 终端启动(退出终端或ctrl+c会退出运行)
./filebeat -e -c filebeat.yml
- 以后台守护进程启动启动filebeats
ohup ./filebeat -e -c filebeat.yml &
- 确认配置不再修改,可用如下命令
//可以防止日志爆盘,将所有标准输出及标准错误输出到/dev/null空设备,即没有任何输出信息。
nohup ./filebeat -e -c filebeat.yml >/dev/null 2>&1 &
2
- 停止运行FileBeat进程
ps -ef | grep filebeat
Kill -9 线程号
2
- FileBeat调试
当FileBeat在服务主机采集应用日志并向Kafka输出日志时可以通过两个步骤验证Filebeat的采集输送是否正常:
- 采集验证:终端执行命令,查看控制台输出,如果服务有异常会直接打印出来并自动停止服务。
./filebeat -e -c filebeat.yml
- 接收验证:Kafka集群控制台直接消费消息,验证接收到的日志信息。
./kafka-console-consumer.sh --zookeeper zk-1:2181,zk-2:2181 --topic app.log
- ElasticSearch或者Kibana验证。如果已经搭建了ELK平台,可根据上传的日志关键属性,于KB或者ES平台查看是否有日志流输入或者在search框中根据host.name/log_topic关键属性来查看是否有落库。
# Kafka集群搭建
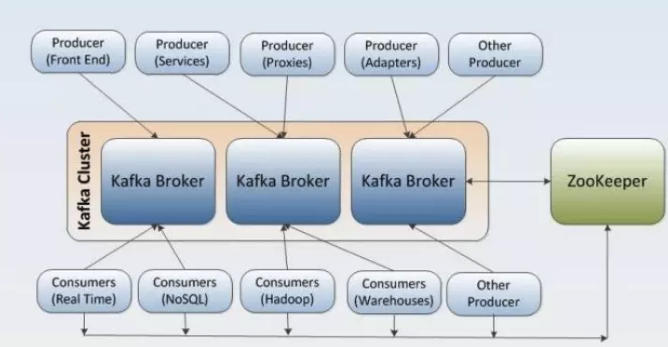
一个典型的Kafka集群包含若干Producer,若干broker、若干Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。下面就提供了一个典型的Kafka+ZooKeeper集群:
- Kafka配置
生产环境中 Kafka 集群中节点数量建议为(2N + 1 )个,Zookeeper集群同样建议为(2N+1)个,这边就都以 3 个节点举例,修改kafka集群的配置文件,以broker1为例进行配置:
$ vim ./config/server.properties
broker.id=1
port=9092
host.name=192.168.0.108
num.replica.fetchers=1
log.dirs=/opt/kafka_logs
num.partitions=3
zookeeper.connect=zk-1:2181,zk-2:2181,zk-3:2181
zookeeper.connection.timeout.ms=6000
zookeeper.sync.time.ms=2000
num.io.threads=8
num.network.threads=8
queued.max.requests=16
fetch.purgatory.purge.interval.requests=100
producer.purgatory.purge.interval.requests=100
delete.topic.enable=true
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
这里比较重要的一个参数配置就是:num.partitions Kafka中的topic是以partition的形式存放的,每一个topic都可以设置它的partition数量,Partition的数量决定了组成topic的log的数量。推荐partition的数量一定要大于同时运行的consumer的数量。另外,建议partition的数量大于集群broker的数量,这样消息数据就可以均匀的分布在各个broker中。
-delete.topic.enable:在0.8.2版本之后,Kafka提供了删除topic的功能,但是默认并不会直接将topic数据物理删除。如果要从物理上删除(即删除topic后,数据文件也会一同删除),就需要设置此配置项为true。
- Kafka运维命令
这里涉及到topic主题的创建、与filebeats调试消息的状态,需要掌握几个有用的运维指令:
查看topic状态
./kafka-topics.sh --describe --zookeeper zk-1:2181,zk-2:2181,zk-3:2181 --topic app.log1查看所有topic列表:
./kafka-topics.sh --zookeeper --zookeeper zk-1:2181,zk-2:2181,zk-3:2181 --list1创建topic
kafka-topics.sh --zookeeper --zookeeper zk-1:2181,zk-2:2181,zk-3:2181 --create --topic app.log --partitions 5 --replication-factor 2` 注意:server.properties 设置 delete.topic.enable=true1
2删除主题数据
./bin/kafka-topics.sh --delete --zookeeper zk-1:2181,zk-2:2181,zk-3:2181 --topic app.log1生产topic的消息
./kafka-console-producer.sh --broker-list kafka-1:9092 kafka-2:9092 --topic app.log1消费topic的消息
./kafka-console-consumer.sh --zookeeper zk-1:2181,zk-2:2181,zk-3:2181 --topic app.log1
- Kafka服务监控
通过以下命令启动了Kafka集群服务以后,尝试创建主题、打印主题列表查看服务状态。
./bin/kafka-server-start.sh -daemon ./config/server.properties
# LogStash
Logstash是一个开源的、服务端的数据处理pipeline(管道),它可以接收多个源的数据、然后对它们进行转换、最终将它们发送到指定类型的目的地。Logstash是通过插件机制实现各种功能的,可以在https://github.com/logstash-plugins (opens new window) 下载各种功能的插件,也可以自行编写插件。
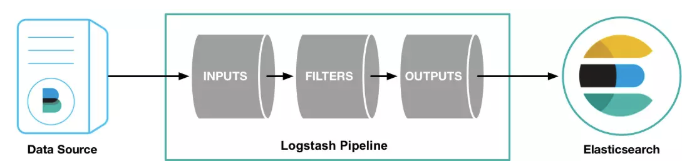
LogStash处理流程
Logstash的数据处理过程主要包括:Inputs, Filters, Outputs 三部分, 另外在Inputs和Outputs中可以使用Codecs对数据格式进行处理。这四个部分均以插件形式存在,在logstash.conf配置文件中设置需要使用的input,filter,output, codec插件,以实现特定的数据采集,数据处理,数据输出等功能
- Inputs:用于从数据源获取数据,常见的插件如file, syslog, redis, beats 等;
- Filters:用于处理数据如格式转换,数据派生等,常见的插件如grok, mutate, drop, clone, geoip等;
- Outputs:用于数据输出,常见的插件如elastcisearch,file, graphite, statsd等;
- Codecs:Codecs不是一个单独的流程,而是在输入和输出等插件中用于数据转换的模块,用于对数据进行编码处理,常见的插件如json,multiline
本实例中input从kafka中获取日志数据,filter主要采用grok、date插件,outputs则直接输出到elastic集群中。logstash的配置文件是可以自定义的,在启动应用时需要制定相应的配置文件。
input {
kafka {
bootstrap_servers => "localhost:9092"
topics => ["nginx-log"]
codec => "json"
}
}
filter {
if "nginx-accesslog" in [tags] {
mutate {
convert => {
"status" => "integer"
"body_bytes_sent" => "integer"
"request_time" => "float"
}
}
}
}
output {
elasticsearch {
hosts => "localhost:9200"
index => "nginx-log-%{+YYYY.MM.dd}"
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
对上述参数进行说明: input,需要指明是kafka来源,broker的ip和端口,主题,codec模式为json(因为经过filebeat采集而来的数据都json化了) filter,grok是一个十分强大的logstash filter插件,通过正则解析任意文本,将非结构化日志数据弄成结构化和方便查询的结构。 output,指定了输出到ES集群,host这里写ES集群的客户端节点即可,index则是对应ES里的检索,一般以【topic+日期】即可。
但是往往复杂的日志系统这些还是不够,需要加一些特殊处理如:异常堆栈需要合并行、控制台调试等。
- 搜集日志时涉及异常堆栈的合并行处理时,可以加上;如果Filebeat已作合并处理此处则不需要了:
input {
stdin {
codec => multiline {
pattern => "^\["
negate => true
what => "previous"
}
}
}
2
3
4
5
6
7
8
9
- 控制台调试过滤器。 很多时候我们需要调试自己的正则表达式是否可用,官方的在线调试并不好用,那么可以通过自己生成的json数据来校验正则的效果,count指定重复生成的次数,message则是待调试的内容:
input {
generator {
count => 1
message => '{"key1":"value1","key2":[1,2],"key3":{"subkey1":"subvalue1"}}'
codec => json
}
}
2
3
4
5
6
7
filter插件由用户自定义填写,启动测试并检查接口,每次调试都要启动一次服务可能会需要等待几秒钟才输出内容到控制台。
./logstash -f /wls/logstash/config/logstash-test.conf
关于LogStash的语法详解和实践指南可以参考:《Logstash 最佳实践》 (opens new window)
# Elasticsearch集群搭建
在ElasticSearch的架构中,有三类角色,分别是Client Node、Data Node和Master Node,搜索查询的请求一般是经过Client Node来向Data Node获取数据,而索引查询首先请求Master Node节点,然后Master Node将请求分配到多个Data Node节点完成一次索引查询。
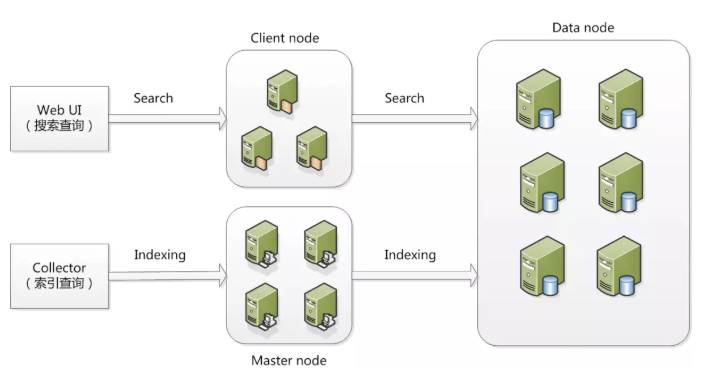
Master Node:主要用于元数据(metadata)的处理,比如索引的新增、删除、分片分配等,以及管理集群各个节点的状态。由于数据的存储和查询都不会走主节点,所以主节点的压力相对较小,因此主节点的内存分配也可以相对少些,但是主节点却是最重要的,因为一旦主节点宕机,整个elasticsearch集群将不可用。所以一定要保证主节点的稳定性。
Data Node:数据节点,这些节点上保存了数据分片。它负责数据相关操作,比如分片的CRUD、搜索和整合等操作。数据节点上面执行的操作都比较消耗CPU、内存和I/O资源,数据节点服务器要选择较好的硬件配置。
Client Node:客户端节点。client node存在的好处是可以分担data node的一部分压力,因为elasticsearch的查询是两层汇聚的结果,第一层是在data node上做查询结果汇聚,然后把结果发给client node,client node接收到data node发来的结果后再做第二次的汇聚,然后把最终的查询结果返回给用户。这样,client node就替data node分担了部分压力。
- 集群配置
第一步即定义修改es集群的配置文件:
$ vim config/elasticsearch.yml
cluster.name: es
node.name: es-node1
node.master: true
node.data: true
network.host: 192.168.0.1
discovery.zen.ping.unicast.hosts: ["192.168.0.2","192.168.0.3"]
discovery.zen.minimum_master_nodes: 2
2
3
4
5
6
7
8
9
集群重要配置项
- node.name 可以配置每个节点的名称
- node.master 可以配置该节点是否有资格成为主节点。如果配置为 true,则主机有资格成为主节点,配置为 false 则主机就不会成为主节点,可以去当数据节点或负载均衡节点
- node.data 可以配置该节点是否为数据节点,如果配置为 true,则主机就会作为数据节点,注意主节点也可以作为数据节点
- discovery.zen.ping.unicast.hosts 可以配置集群的主机地址,配置之后集群的主机之间可以自动发现,需要剔除自己。
- discovery.zen.minimum_master_nodes: 为了防止集群发生“脑裂”,通常需要配置集群最少主节点数目,通常为 (主节点数目 / 2) + 1
- 服务启停
通过 -d 来后台启动
$ ./bin/elasticsearch -d
打开网页 http://192.168.0.1:9200/ (opens new window), 如果出现下面信息说明配置成功
{
name: "es-node1",
cluster_name: "es",
cluster_uuid: "XvoyA_NYTSSV8pJg0Xb23A",
version: {
number: "6.2.4",
build_hash: "ccec39f",
build_date: "2018-04-12T20:37:28.497551Z",
build_snapshot: false,
lucene_version: "7.2.1",
minimum_wire_compatibility_version: "5.6.0",
minimum_index_compatibility_version: "5.0.0"
},
tagline: "You Know, for Search"
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
集群服务健康状况检查,可以再任意节点通过执行如下命令,如果能发现列表展示的主节点、客户端和数据节点都是一一对应的,那么说明集群服务都已经正常启动了。
curl "http://ip:port/_cat/nodes"
关于ES的详细原理与实践,推荐《Elasticsearch 权威指南》 (opens new window)
# Kibana
Kibana是一个开源的分析和可视化平台,设计用于和Elasticsearch一起工作,可以通过Kibana来搜索,查看,并和存储在Elasticsearch索引中的数据进行交互。kibana使用JavaScript语言编写,安装部署十分简单,可以从elastic官网 (opens new window)下载所需的版本,这里需要注意的是Kibana与Elasticsearch的版本必须一致,另外,在安装Kibana时,要确保Elasticsearch、Logstash和kafka已经安装完毕。
- Kibana的配置
找到配置文件kibana.yml并修改
$ vim config/kibana.yml
server.port: 5601
server.host: "192.168.0.1"
elasticsearch.url: "http://192.168.0.1:9200"
2
3
4
5
涉及到三个关键参数配置: server.port: kibana绑定的监听端口,默认是5601 server.host: kibana绑定的IP地址 elasticsearch.url: 如果是ES集群,则推荐绑定集群中任意一台ClientNode即可。
- Kibana运维命令
启动服务:
nohup ./bin/kibana &
停止服务
ps -ef | grep node
kill -9 线程号
2
服务启动以后可以通过访问:http://192.168.0.1:5601/
# 总结
综上,通过上面部署命令来实现 ELK 的整套组件,包含了日志收集、过滤、索引和可视化的全部流程,基于这套系统实现分析日志功能。同时,通过水平扩展 Kafka、Elasticsearch 集群,可以实现日均亿级的日志实时存储与处理,但是从细节方面来看,这套系统还存着许多可以继续优化和改进的点:
- 日志格式需优化,每个系统收集的日志格式需要约定一个标准,比如各个业务系统在定义log4j或logback日志partern时可以按照【时间】【级别】【全局Traceid】【线程号】【方法名】【日志信息】统一输出。
- Logstash的正则优化,一旦约定了日志模式,编写Logstash的自定义grok正则就能过滤出关键属性存放于ES,那么基于时间、traceId以及方法名的查询则不在堆积于message,大大优化查询效率。
- ES存储优化,按照线上机器的业务量来看,每天TB级的日志数据都写入ES会造成较大的存储压力,时间越久的日志利用价值则越低,可以按照7天有效期来自动清理ES索引优化存储空间,参考【ES清理脚本】 (opens new window)。
- 运维优化,一个复杂日志平台在运维方面有着巨大的成本,这里涉及到了Kafka、ZooKeeper、ELK等多个集群环境的维护,除了提供统一的集群操作指令以外,也需要形成对整套日志平台环境的监控视图。
参考文档: